在主流的机器学习框架(TensorFlow、PyTorch、MXNet 等)中,模型通常被表征为数据流图(dataflow graph)。图上的边代表流动的张量(tensor);节点则是算子(computational operator,简写为 $op$),例如矩阵相乘(matmul)、激活函数(activation)等。训练一个 DL 模型时,每一轮迭代可以划分为如下三个步骤:
- 将给定的 mini-batch data 进行前向传播(forwarding),将最终输出的数值和样本标签代入均方误差(MSE)等公式得到 loss;
- 根据反向传播获得 loss 在各层对参数的梯度 1;
- 通过优化器(optimizer,例如 SGD、AdaGrad、Adam 等)对参数进行更新。
模型的开发者仅需要通过框架提供的 API 定义该模型的数据流图并指定超参数即可,剩下的内容全部由框架完成。然而,随着模型增大,单个 GPU 已经无法在可以接受的时间范围内完成训练,由此分布式训练便诞生 —— 它通过设计各种并行策略让上述三个步骤的每个阶段都可以被分发到不同的 GPU 上执行。
本文要讨论的工作 Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning 发表在 OSDI '22 上,该工作设计并开发了一款工具,名为 Alpa,它能够根据内部实现的策略,将给定的模型自动化地进行并行拆分,从而加速模型训练。模型开发者只需要在形如 train_step() 这类 Jax 函数 2 上方添加 Alpa 提供的 @parallelize 装饰器即可,如图 1 所示:
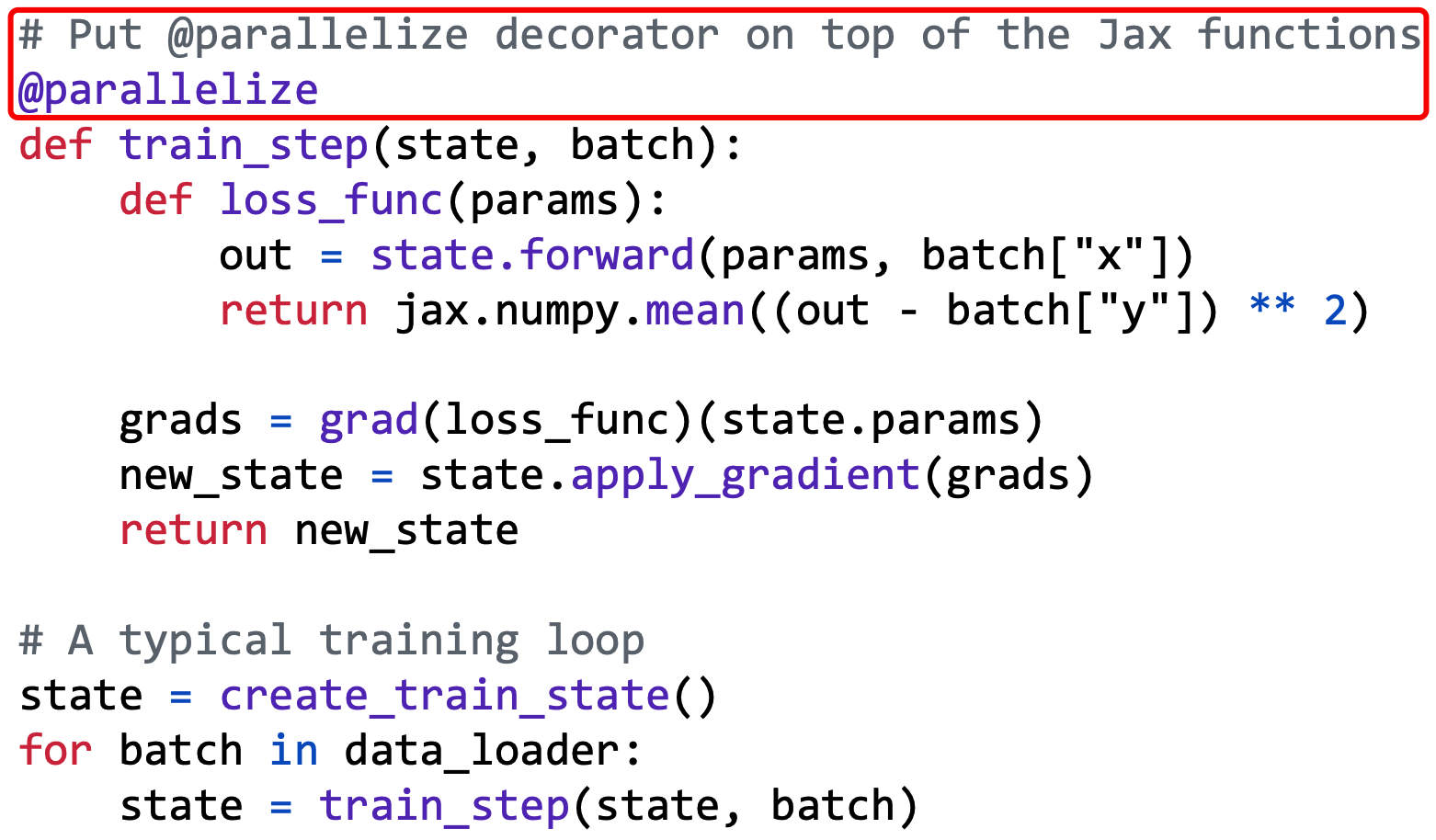
接下来,我会深入拆解 Alpa 的工作原理。
1 DL 模型训练的并行策略
数据并行(Data Parallelism,简写为 DP)。 在 DP 中,mini-batch data 被划分为多个部分,每个部分交由一个 worker 来训练。每个 worker 都是模型的完整备份(replica)。每一轮迭代包含如下行为:
- 每个 worker 根据自己分得的数据计算模型梯度(执行上文所述的三个步骤中的前两个);
- 这些 worker 以同步(或异步)、中心化(或去中心化)的方式对梯度进行同步(基于 all-reduce 操作),最终保证每个 worker 最终具有一致的、聚合后的梯度。
- 每个 worker 在本地调用 optimizer 更新模型参数。
Parameter Server (PS) / worker 架构和 all-reduce 架构是最典型的同步中心化 DP,也是目前主流的深度学习框架所支持的。在 PS/worker 架构中,梯度的同步由 PS 完成:PS 收集来自全部 worker 的 local gradients 并对它们进行聚合 $\to$ PS 在本地执行 optimizer 更新参数 $\to$ PS 将更新后的模型参数发送给每个 worker 3。在 PS/worker 架构中,worker 是 GPU-intensive 的,而 PS 通常是 CPU-intensive 的。图 2 给出了两种典型的 PS/worker 架构的部署方案。在方案 (b) 中,虚线代表的是节点内通信,其通信开销显著低于跨节点通信。
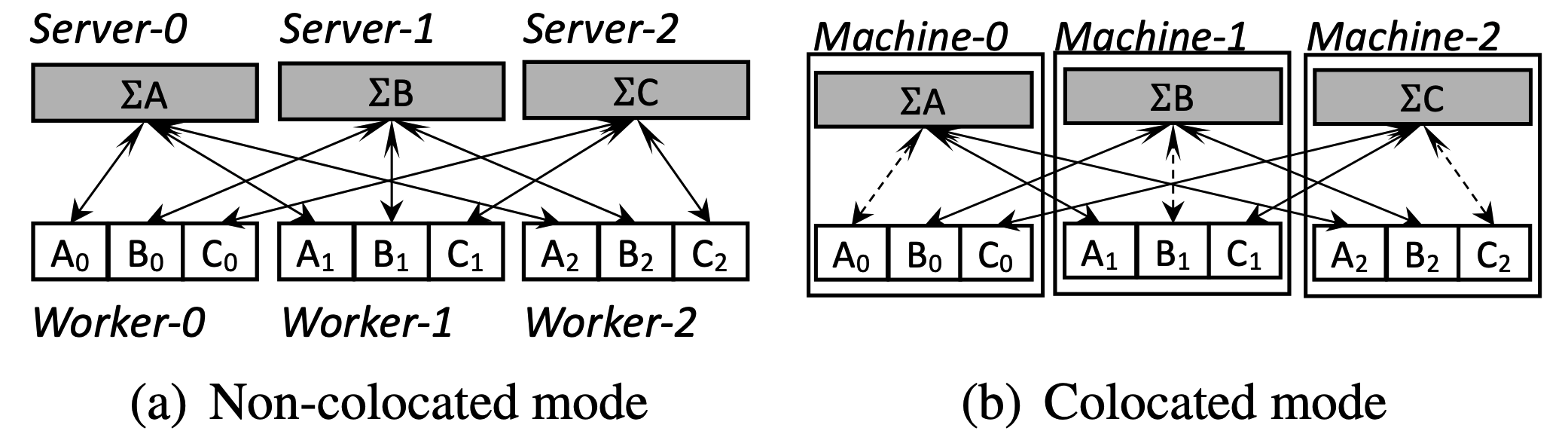
值得注意的是,在图 2 中,不论是 (a) 还是 (b),均有三个 PS,不同 PS 负责更新模型参数的不同划分。这里其实暗含了流水线并行的策略,我会在下文中给予描述。
算子并行(Operator Parallelism,简写为 OP)。 在 OP 中,一个特定的算子 $op$ 被沿着 “非样本的维度(non-batch axes)” 进行划分(partition,或 sharding),$op$ 的不同部分在不同 GPU 上执行,最后通过相应的 collective communication 操作 4 将结果进行合并。注意,所谓对算子的划分,本质上是对参与该算子运算的 tensor 进行划分。这会引入通信开销 —— 以 matmul 为例,如果输入的两个矩阵的不同部分被分散到了不同 GPU 上,则执行运算时,所有参与的 GPU 需要遵循同一个 collective communication 模式(all-reduce、all-gather、all-to-all 等)从不同 GPU 上获取输入矩阵的不同部分。除此之外,如何进行最优划分是一个很困难的问题,Alpa 的策略是均匀划分 —— tensor 被划分为等大小的部分,每个部分被均匀地分发到一个 GPU 上 5。
流水线并行(Pipeline Parallelism,简写为 PP)。 PP 将一个 DL 模型划分为多个阶段(stage),每个 stage 都是一个(或多个)$op$ 的集合。每一个 stage 将会被分发到一组 GPU 上;此外,PP 将 data batch 进一步划分为 microbatch,并将 microbatch 在各个 stage 上以流水线的方式依次进行前向和反向传播。
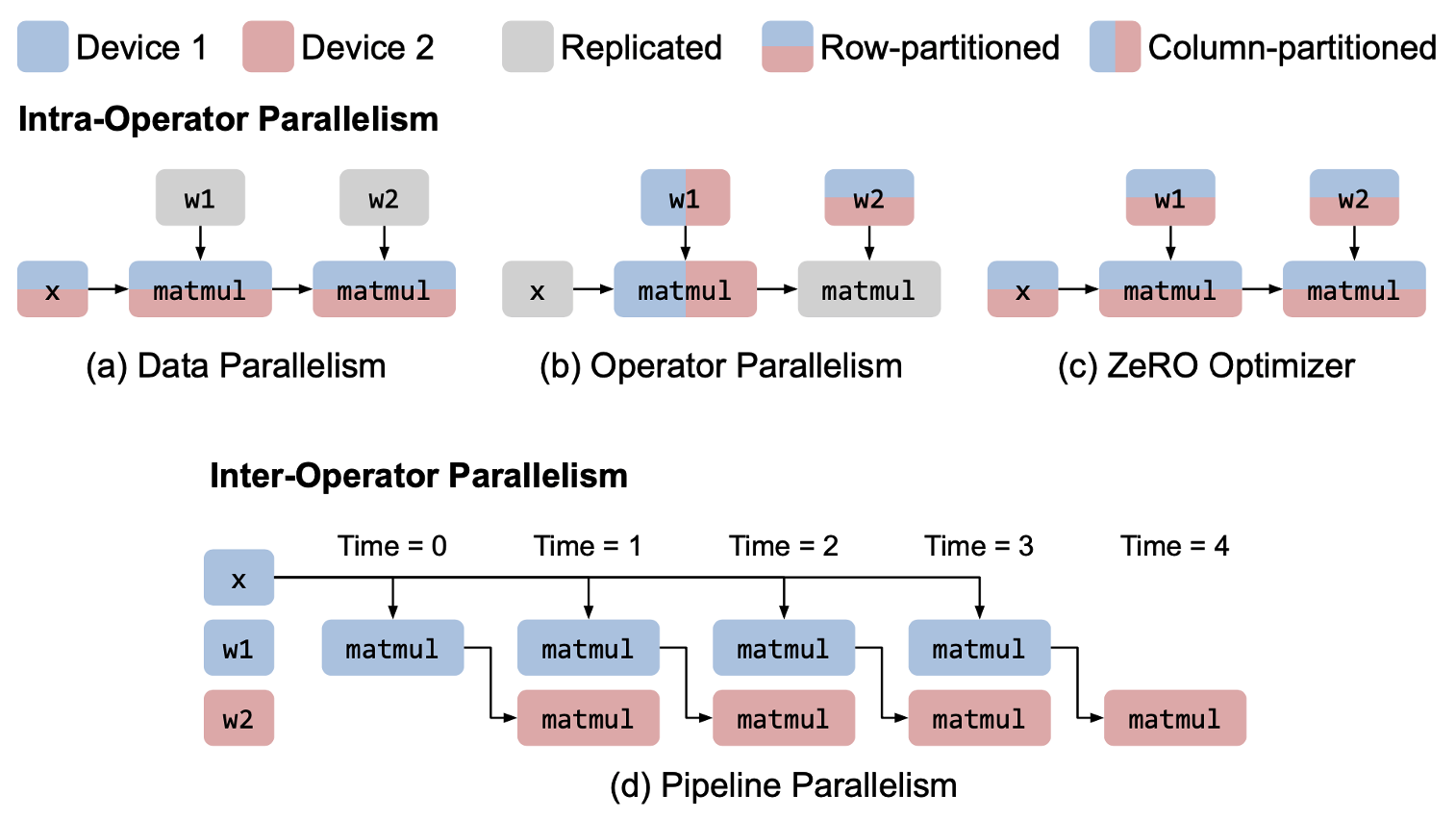
图 3 展示了一个两层的 MLP 模型的不同并行策略。图 3(c) 中,算子在「参数更新」的阶段被 sharing,这种方法被称作 ZeRO 6。这是对 DP 的一种改进。图 3(d) 中,模型被分成了两个 stage,且一个 mini-data batch 被切分成了 4 个 microbatch。图 3(d) 可视化的是「同步 1F1B」(one forward,one backward)模式。这个示意图没有反映出相邻 stage 的数据传输开销。图 4 给出了一个更加切实的流水线示意图。
对于任意模型,当我们想要为其设计一个优秀的并行策略时,我们需要考虑如下问题:
- 如果采用了 DP,则需要多少个 replica?
- 如果采用了 OP,则沿着哪个(些)维度对
$op$进行划分? - 如果采用了 PP,哪些
$op$(或者 layer)应当被划归到一个 stage、且整个模型打算划分为多少个 stage? - 如何将上述三种并行策略进行组合,充分提高训练的吞吐量?
- 模型的每一个子部分(stage、tensor),要映射到具有何种计算性能和带宽的 GPU 上执行?
在现有的工作中,针对每个特定的模型,并行策略都是手动设计的,这不仅繁琐复杂,而且对开发者的经验技能也提出了较高的要求。对此,Alpa 的作者提出了一种具有层次结构的并行技术,它将上述三种并行策略划归到如下两种方案中:
- 算子内并行(intra-
$op$parallelism)。Intra-$op$parallelism 将算子沿着一个或多个维度(batch or non-batch axes)进行 sharding,因此是 DP 和 OP 的组合。Intra-$op$parallelism 会导致额外的 split 和 merge 操作,因此会带来额外的通信开销; - 算子间并行(inter-
$op$parallelism)。Inter-$op$parallelism 将模型划分到不同的 stage,并且按照流水线的方式将不同的 stage 在不同的 GPU 组上执行。这就是 PP。Inter-$op$parallelism 只需要让相邻的 stage 进行通信,因此通信的开销相对较低,然而每个 stage 需要等待前序将数据传递过来后才能执行,这可能会造成 GPU 的空闲,从而拉低吞吐量。
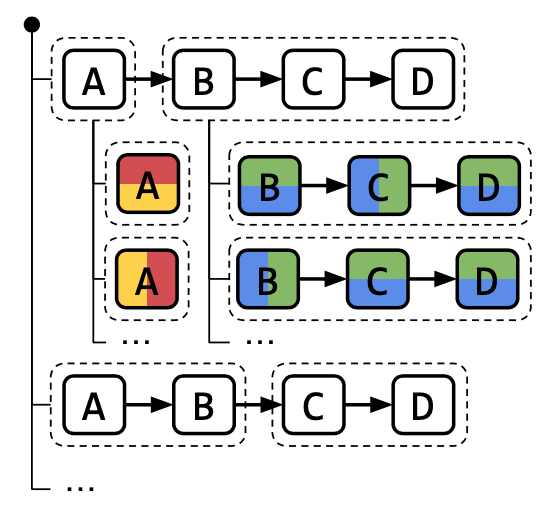
Alpa 充分利用了这两种方案的特点,它试图将每个 stage 映射到一组 内部高速互联 的 GPU 组 7 上。首先,对于模型中的每个 $op$,Alpa 将其 intra-$op$ parallelism 建模为一个整数规划问题并利用现有 solver 给出(次)最优解;其次,充分利用每个 $op$ 的最优 intra-$op$ parallelism 方案,利用动态规划给出 stage 的划分方案(最优子结构为:对于任意 $op$,是否将该 $op$ 划分到一个新的 stage 中)并确定每个 stage 所要映射的 GPU 组。这种分层求解的方案,在一定程度上,很好地回答了上述 5 个问题。Alpa 的分层结构如图 5 所示。其中,$A \to B \to C \to D$ 是一个符合 XLA’s HLO 形式 8 的 DL 模型的数据流图。$A$ 被划分到一个 stage 中,$B$、$C$、$D$ 被划分到另一个 stage 中。每个 stage 内部的 $op$ 有各自的 intra-$op$ parallelism 方案。
接下来,我将结合 Alpa 的架构图进一步介绍 Alpa 的工作原理。
2 Alpa 架构综述
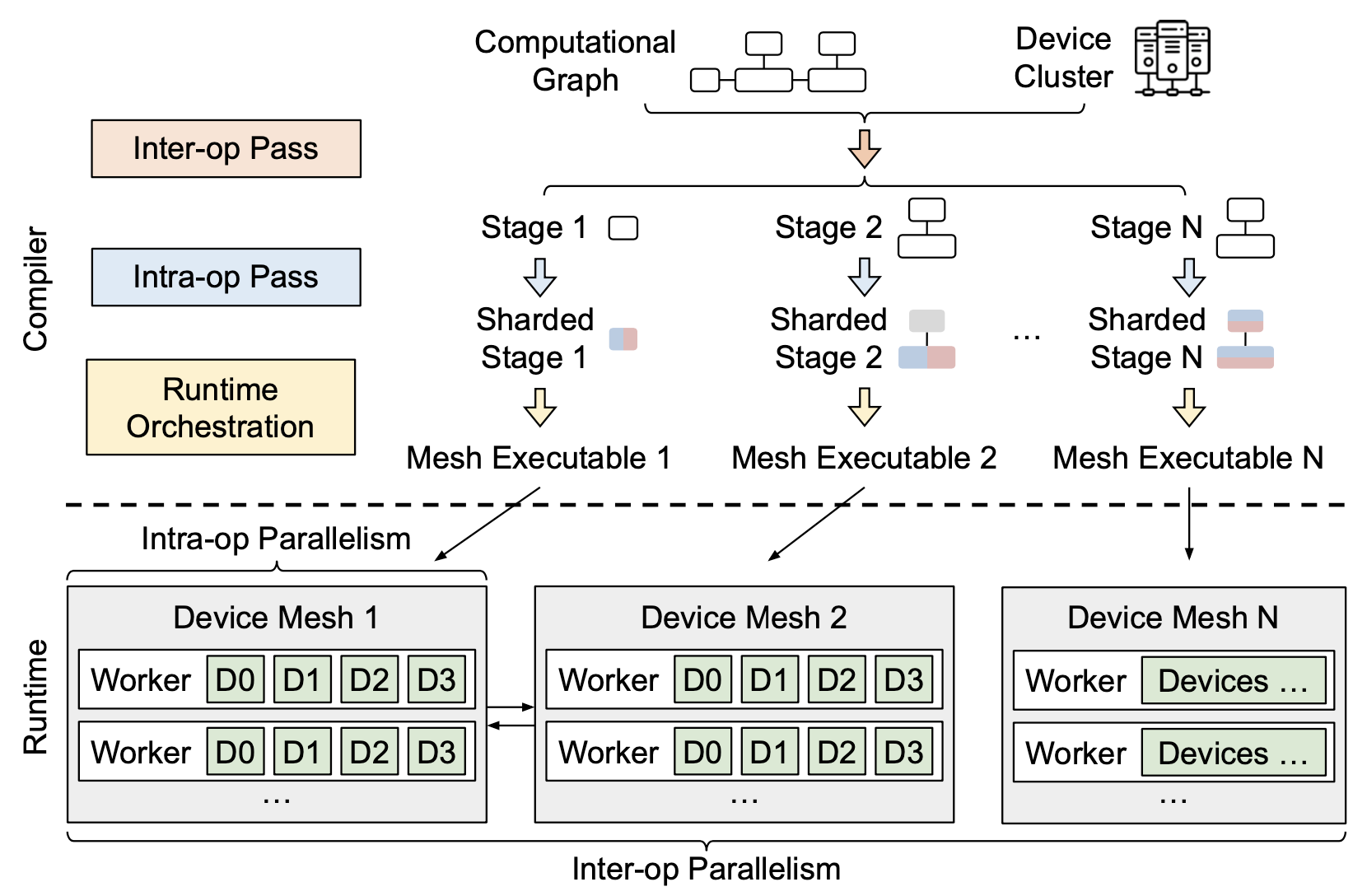
Alpa 的架构如图 6 所示。如前文所述,Alpa 将并行策略的设计划分成了两个层次。首先,在 intra-$op$ parallelism 这一层,对于任意给定的子图(模型数据流图的任意子部分)和相应的 GPU 组(作者将其命名为 GPU device mesh —— 这些 GPU 组成了一个二维的平面,整个 GPU 组内部横向 / 纵向高速相连),Alpa 以最小化该子图上的开销为目标计算该子图内的任意 $op$ 在给定的 GPU 组上的最优 intra-$op$ parallelism 方案。这个过程被建模为一个整数规划问题,Alpa 通过调用现有的 solver 来求解它。在 inter-$op$ parallelism 这一层,Alpa 以最小化总延迟为目标,充分利用各个 $op$ 的最优 intra-$op$ parallelism 方案,给出了如下三个子问题的解:
- 如何将整个数据流图划分成 stage(多少个 stage、以及每个 stage 包含哪些
$op$)? - 如何将全体 GPU 划分成互不相同的 GPU 组?
- 每个 stage 应该被映射到哪个 GPU 组上执行?
对于子问题 2,Alpa 枚举了所有可能的 GPU 组 9,并将子问题 1 和 3 统一建模为一个动态规划问题,通过迭代其最优子结构来求解。可以预见,这个动态规划在求解的过程中会反复调用 solver 求解 intra-$op$ parallelism 所面临的整数规划问题,整个算法的复杂度其实很高。关于这一点我会在后文展开分析。
接下来我将依次阐述 intra-$op$ parallelism 和 inter-$op$ parallelsim 的细节。
3 算子内并行
在 intra-$op$ parallelism 这一层,Alpa 需要对任意给定的子图和相应的 GPU 组,给出该子图的每一个 $op$ 在该 GPU 组上的最优并行方案。这个过程建立在如下两个假设之上:
- 给定的 GPU 组内的所有 GPU 是同构的(例如,都是同一个型号),它们具有相同的计算性能。
- 任意
$op$均被均匀划分,即,参与运算的 tensor 在任意维度上均被划分为等大小的不同部分。
3.1 Sharding、Resharding 与通信开销
接下来,我们以 matmul 运算为例,展示最优 intra-$op$ parallelism 的求解过程。
GPU 组(device mesh)。 一个 GPU 组是一组同构的 GPU 的二维逻辑平面。GPU 组中的任意 GPU 之间可以沿着第 0 个维度($dim = 0$,行)或第 1 个维度($dim = 1$,列)进行通信,同一个维度上通信链路具有相同的带宽。不妨设给定的 GPU 组的大小为 $n_0 \times n_1$。
Sharding。 我们用如下标记来描述一个 tensor 的 sharding 方案:对于任意 $N$ 维 tensor,它的 sharding 方案用 $X_0 X_1 ... X_{N-1}$ 来表示,其中每个 $X_i \in \{ S, R \}$。若 $X_i = R$,则意味着该 tensor 将沿着第 $i$ 个维度被复制(replicating);若 $X_i = S$,这意味着该 tensor 将沿着第 $i$ 个维度被均匀切分(partitioning, or sharding)。进一步地,
- 若
$X_i = S^0$,则意味着该 tensor 沿着第$i$个维度被均匀切分成$n_0$份,每一份分别被放置在 GPU 组的每一行上; - 若
$X_i = S^1$,则意味着该 tensor 沿着第$i$个维度被均匀切分成$n_1$份,每一份分别被放置在 GPU 组的每一列上; - 若
$X_i = S^{01}$,则意味着该 tensor 沿着第$i$个维度被均匀切分成$n_0 \times n_1$份,每一份按照先行后列的方式被放置在 GPU 组的每一个 GPU 上; - 若
$X_i = S^{10}$,则意味着该 tensor 沿着第$i$个维度被均匀切分成$n_1 \times n_0$份,每一份按照先列后行的方式被放置在 GPU 组的每一个 GPU 上。
表 1 给出了一个大小为 $N \times M$ 的二维 tensor(即矩阵)在一个大小为 $2 \times 2$ 的 GPU 组上的所有 sharding 方案。

为了方便读者理解,我将表 1 可视化为图 7。

值得注意的是,即使是矩阵相乘,就已经有如此之多的 sharding 方案,当扩展到一般的 tensor 相乘时,可行的 sharding 方案必然是相当多的。Alpa 是先枚举每一个 $op$ 的每一种 sharding 方案,然后根据整数规划确定最优的那个。工作量可见一斑。
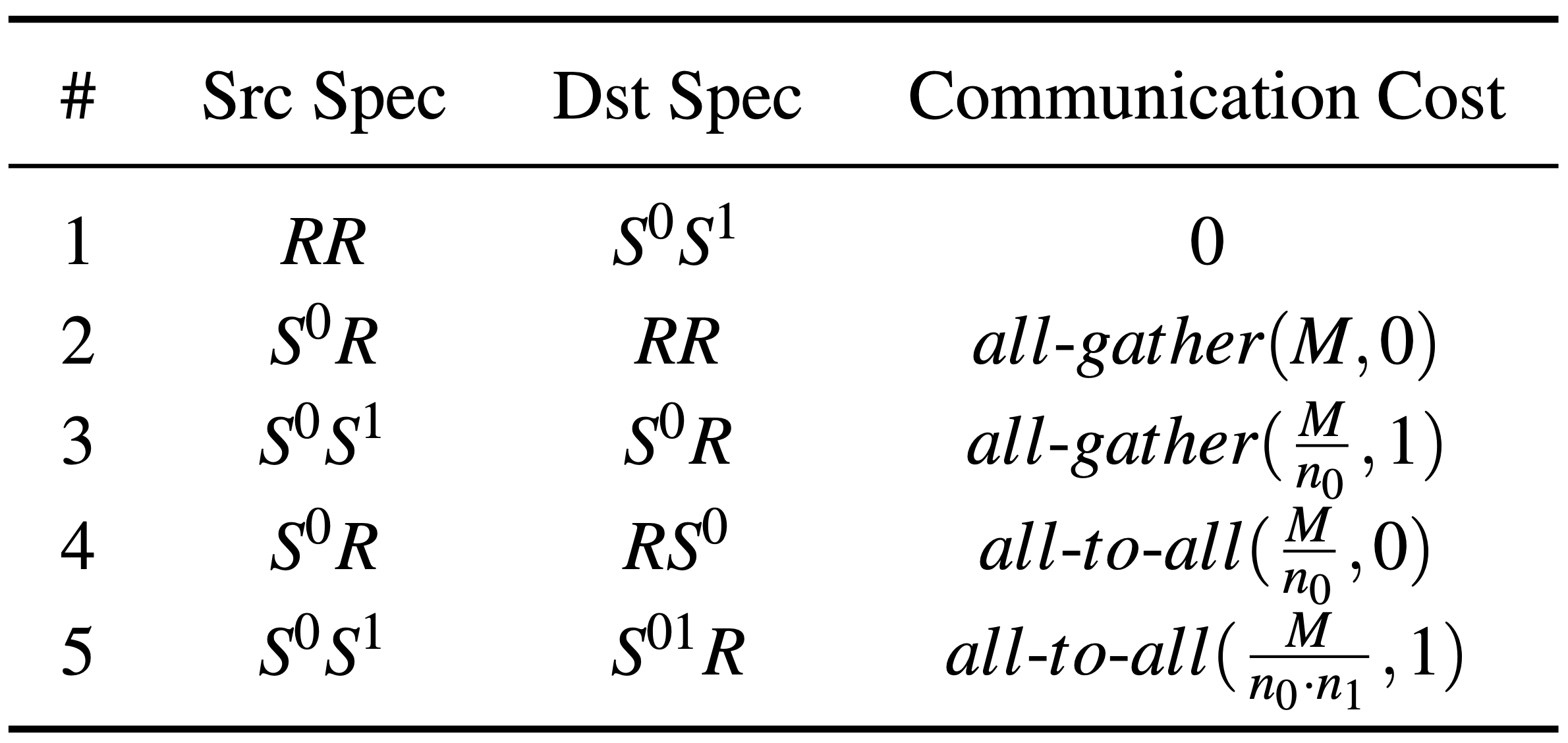
Resharding。 对于任意 $op$,如果输入的 tensor 不符合我们为该 $op$ 指定的 sharding 方案,我们在执行 $op$ 前需要将其 resharding。表 2 给出了从不同输入到不同输出的 resharding 方案的通信开销。以 Case #1 为例,每个 GPU 只需要抛弃自己不需要关心的部分即可,因此 communication cost 为 0。Case #4 和 Case #5 则涉及 GPU 组内数据的 “行列互换”,因此需要 all-to-all 操作。
基于对 sharding 和 resharing 的讨论,表 3 枚举了 matmul 的部分并行策略。这里 matmul 可以写成:$C_{b,i,j} = \sum_k A_{b,i,k} B_{b,k,j}$,其输入和输出均为三维的 tensor,第一个维度代表 batch axis,后两个则代表 feature。

Case #1 的可视化如图 8 所示。以 $C_{b,1,1}$ 为例,它的计算公式为 $A_{b,1} B_{b,1}$,这两个输入均被放置在第一行第一列的 GPU 上,因此,其计算无需任何跨 GPU 通信。
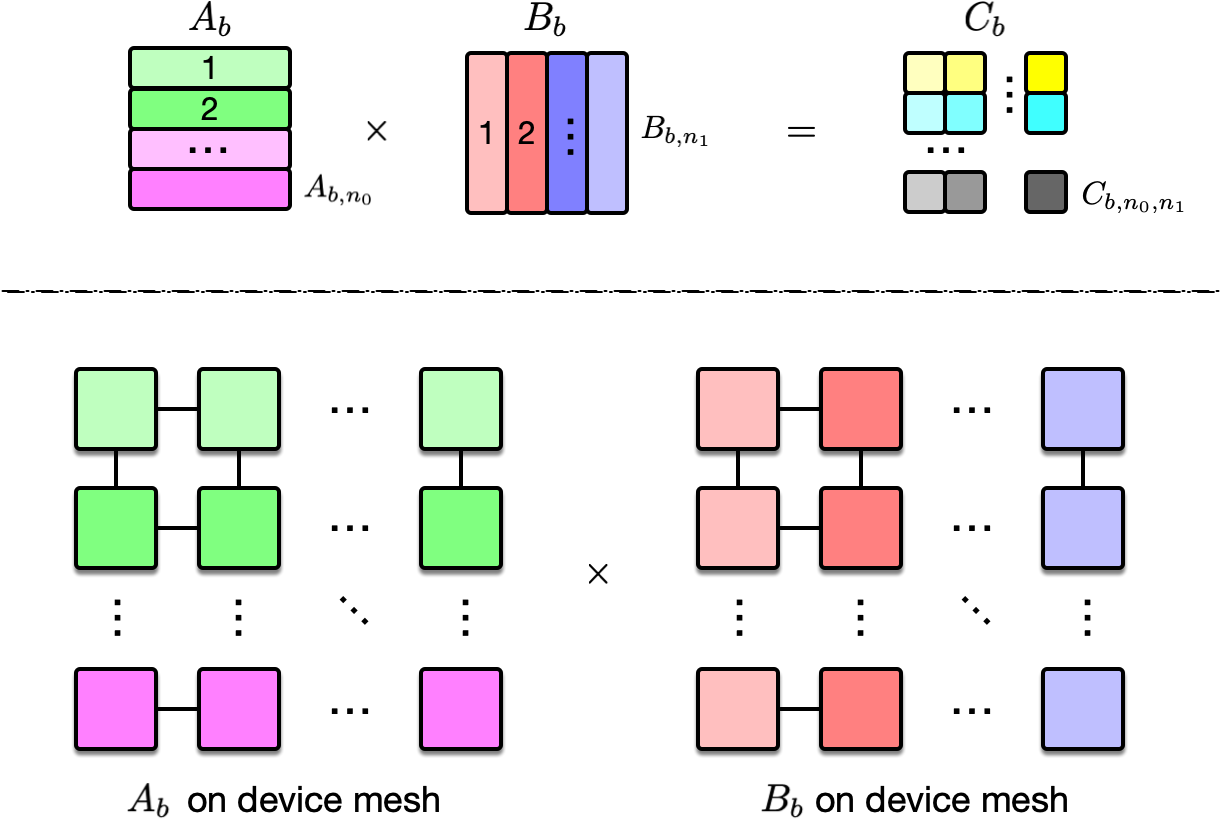
Case #2 的可视化如图 9 所示。以 $A_b$ 的第一行 $A_{b,1,:}$ 和 $B_b$ 的第一列 $B_{b, :, 1}$ 之间的运算为例,即对应位置相乘,结果相加:$\sum_k A_{b,1,k} B_{b,k,1}$。因为 $A_{b,1,k}$ 和 $B_{b,k,1}$ 均被放置在第一行第 $k$ 列的 GPU 上,因此运算 $A_{b,1,k} B_{b,k,1}$ 无需任何通信,不妨将 $A_{b,1,k} B_{b,k,1}$ 记为 $T_{b,k}$。接下来要做的事情是:将第一行每一列($\forall k$)的 GPU 上存放的中间结果 $T_{b,k}$ 按列相加,得到 $\sum_k T_{b,k}$,并将这个结果广播给第一行所有 GPU —— 这就是按列进行的 all-reduce 操作,且需要 reduce 的 data size 为 $\frac{M}{n_0}$,因为 $B_k$ 是按行进行切分的。
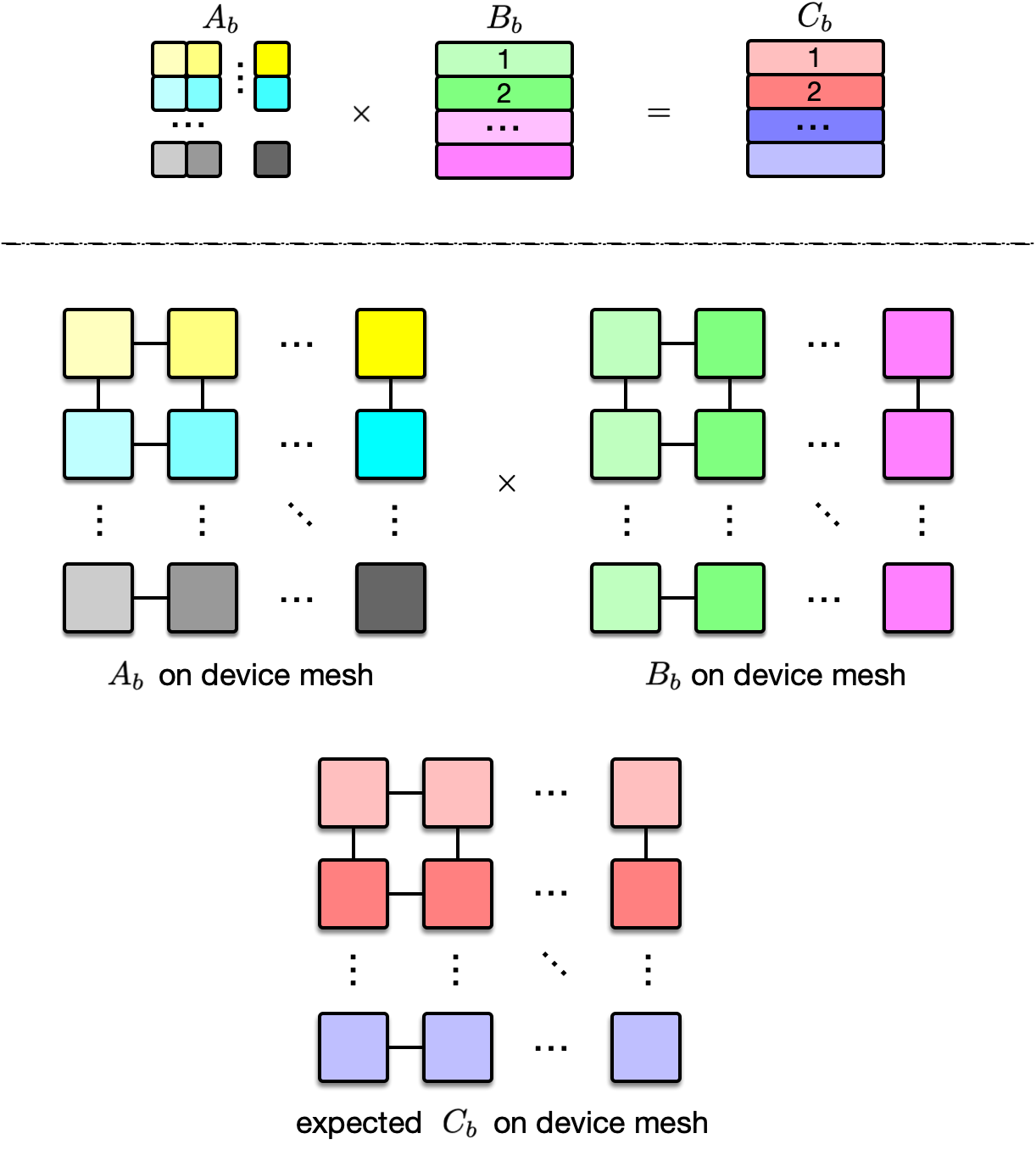
表 3 给出的是 matmul 这一 $op$ 的部分并行策略(非全部)。对于所有的 $op$,大约有 80 种,Alpa 的作者都枚举了其可能的并行策略。接下来,我将展示 Alpa 的作者是如何为每个 $op$ 选择出最优的并行策略的。
3.2 整数规划
对于任意给定的子图 $G = (V,E)$,其中节点 $v \in V$ 代表 $op$,$e \in E$ 代表 tensor 的流动,Alpa 通过求解一个整数规划来计算 $G$ 中每一个 $op$ 的最优并行策略。具体地,不妨用 $k_v$ 表示节点 $v$ 所有可能的并行策略的个数,且分别用 $\vec{c}_{v} \in \mathbb{R}^{k_v}$ 和 $\vec{d}_v \in \mathbb{R}^{k_v}$ 表示节点 $v$ 各并行策略的通信和计算开销。我们将自变量定义为 $\vec{s}_v \in \{ 0,1 \}^{k_v}$,$s_{vi} = 1$ 代表 $v$ 的第 $i$ 个并行策略被选中。对于每条边 $e_{uv}$,resharding 开销被记录在矩阵 $R_{uv}$ 上。以最小化子图 $G$ 上的全部计算通信开销为目标,我们可以得到如下整数规划问题 10:
$$ \begin{aligned} \mathcal{P}_1: \min_{\{ \vec{s}_v \}_{v \in V}} &\sum_{v \in V} \vec{s}_v^\top (\vec{c}_v + \vec{d}_v) + \sum_{e_{uv} \in E} \vec{s}_u^\top R_{uv} \vec{s}_v, \\ s.t. \quad &\vec{s}_v \in \{ 0,1 \}^{k_v}, \sum_i s_{vi} = 1, \forall v \in V. \end{aligned} $$
$\mathcal{P}_1$ 实际上是一个二次规划问题,可能是出于降低计算复杂度的需要,Alpa 将目标函数的第二部分 linearize 之后再进行求解。问题已经形成了,然而,其中的参数 $\vec{c}_v$、$\vec{d}_v$ 和 $R_{uv}$ 该如何获取呢?最简单的方式当然是 profiling。即,对于每个 $op$ 的每个并行策略,反复测试其计算和通信开销,然后用这些经验值的平均来作为对这些参数的估计 11。Alpa 采用了一种更聪明的方式来获取这些参数的值。对于每一个 $\vec{c}_v$ 和 $R_{uv}$,Alpa 计算需要传输的总数据量,然后直接将该值除以 device mesh 各维度的带宽来得到。对于 $\vec{d}_v$,Alpa 直接将它们置为 0。作者给出的理由是:
- 对于 computation-intensive 的
$op$$v$,Alpa 不允许重复计算 12,且每个 GPU 分得的工作量都是相同的,即$d_{v,i_1} \equiv d_{v,i_2}, \forall i_1, i_2$; - 对于 computation-nonintensive 的
$op$,和通信开销相比,计算开销可以忽略不计。
对于这个调整过的整数线性规划问题,Alpa 调用现有的 solver 求解。在实现层面,Alpa 还做了一些优化,例如将 all-reduce 替换为「先 reduce-scatter、后 all-gather」等。从而尽可能降低实际通信开销。
4 算子间并行
在 inter-$op$ parallelism 阶段,Alpa 以最小化「模型训练的端到端延迟」为目标,将整个模型划分为多个 stage,并确定每个 stage 应当被映射到的 GPU 组。
4.1 流水线并行的端到端时延
不妨将整个模型的所有 $op$ 按照拓扑顺序依次记为 $o_1, ..., o_K$。假设我们将模型划分为 $S$ 个 stage,每个 stage $s_i$ 包含 $(o_{l_i}, ..., o_{r_i})$ 这些 $op$ 13;此外,假设每个 stage $s_i$ 被分配给一个大小为 $n_i \times m_i$ 的 device mesh,它是大小为 $N \times M$ 的全体 GPU 的一个子部分。我们用
$$ t_i := t_{intra} \Big(s_i, Mesh(n_i, m_i)\Big) $$
表示在该 device mesh 上执行 stage $s_i$ 的最短时延(将 $s_i$ 和 device mesh 带入章节 3.2,通过求解线性整数规划得到 $t_i$),用 $B$ 表示 microbatch 的个数,则整个模型以流水线并行的方式进行训练的端到端最短时延为
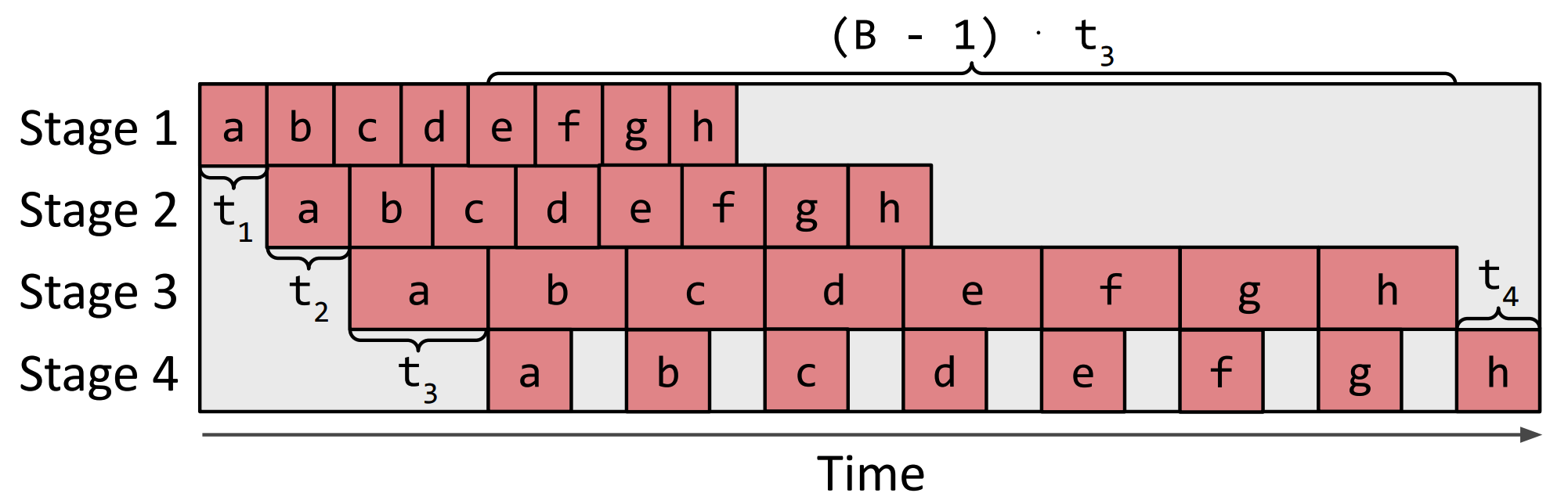
$$ \begin{equation} T^* = \min_{s_1, ..., s_S;(n_1, m_1), ..., (n_S, m_S)} \bigg\{ \sum_{i=1}^S t_i + (B - 1) \cdot \max_{1 \leq j \leq S} \{ t_j \} \bigg\}. \tag{e.q. 1} \end{equation} $$
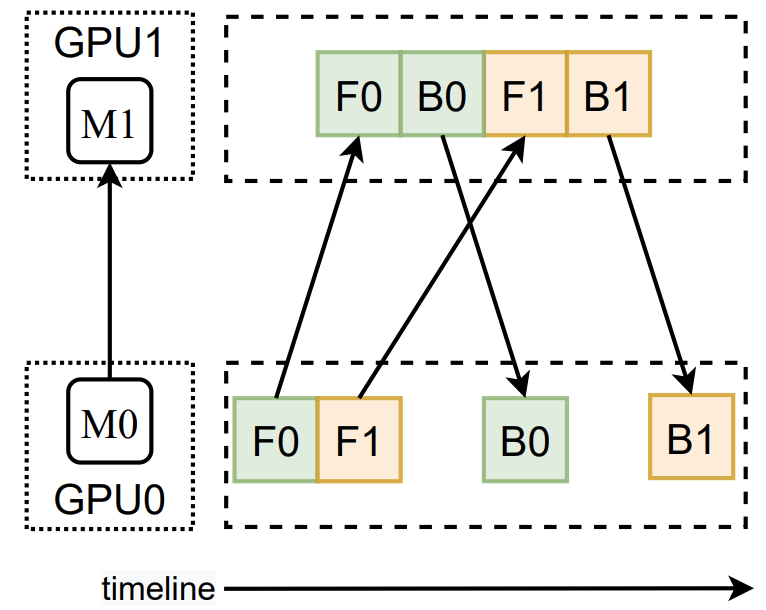
图 10 给出了 $(\textrm{e.q. 1})$ 的示意图。该公式意为,端到端时延包含两个部分,其一是所有 stage 的时延之和,其二则是最慢的 stage 的时延的 $B-1$ 倍。$(\textrm{e.q. 1})$ 能成立的重要前提是:所有相邻 stage 的通信开销均为 0。Alpa 对流水线的建模参考了 GPipe —— 这是第一个提出流水线并行的工作 14。在对应的论文中,作者给出了如图 11 所示的示意图。图 11(c) 在流水线中同时可视化了正向传播和反向传播。
由图 11(a) 可知,stage $s_k$ 的反向传播 $B_k$ 依赖于其正向传播 $F_k$ 的数据和其后继的反向传播 $B_{k+1}$ 的数据,因此,我们可以将 $F_k$ 的 $op$ 和对应 $B_k$ 上的 $op'$ 放置在同一群 GPU 上,从而尽可能降低通信开销。
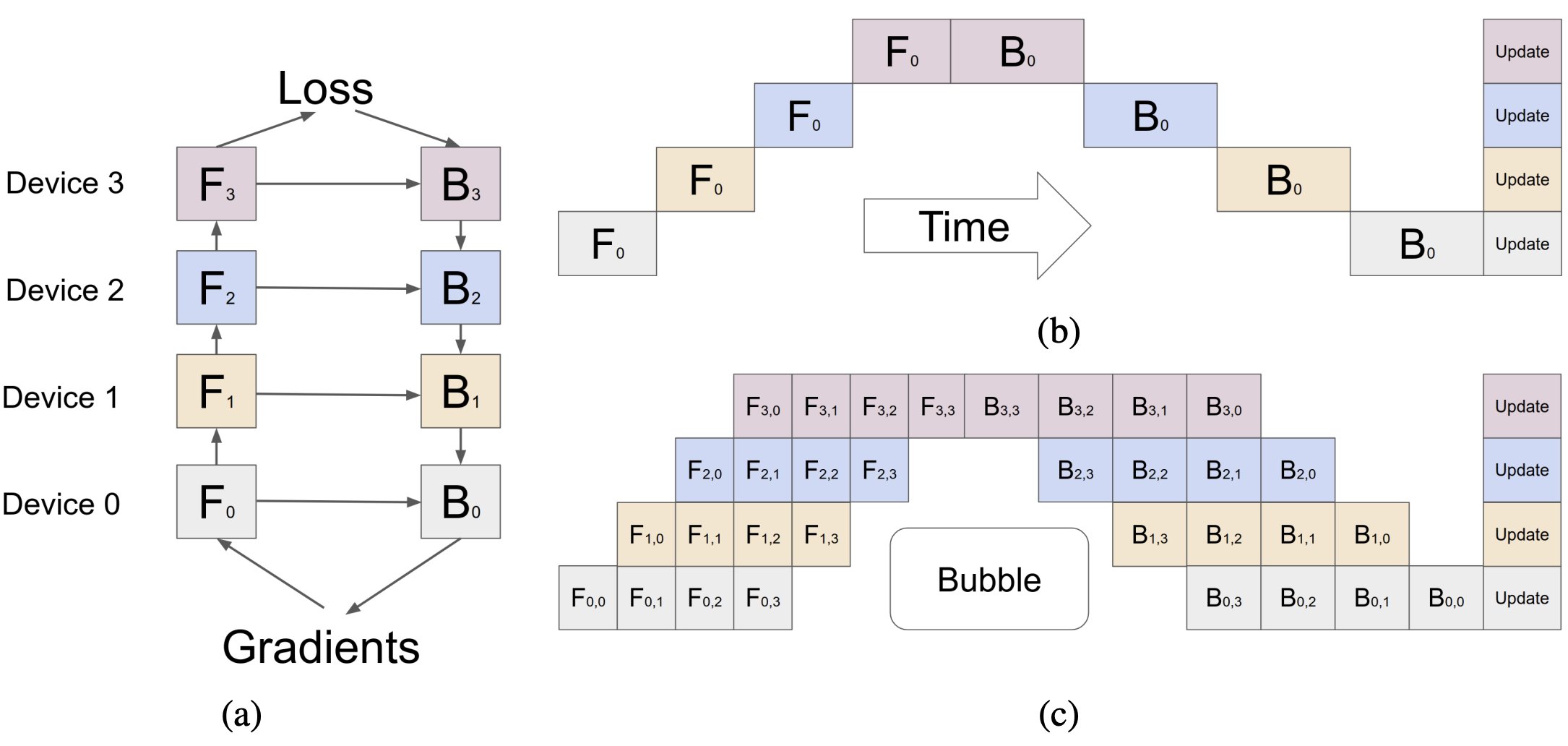
注意,图 10 可视化的部分实际上是图 11(c) 中从 $F_{3,3}$ 开始的部分。
4.2 动态规划
Alpa 将全体 GPU 划分为多个 device mesh。为了简化问题,Alpa 只考虑如下两种形式的 mesh —— 第一种(one-dimensional):$(1,1), (1,2), ..., (1, 2^m)$;第二种(two-dimensional):$(2, M), (3, M), ..., (N, M)$。作者证明了这些 device mesh 是对大小为 $N \times M$ 的二维平面的一个划分(disjoint union),即满足 $\sum_{i=1}^S n_i \cdot m_i = N \cdot M$。
接下来,我们给出动态规划的 formulation。这个动态规划枚举所有的 $t_{max} := \max_{1 \leq j \leq S} t_j$,然后对于每个 $t_{max}$,最小化 $t_{total} (t_{max}) := \sum_{1\leq i \leq S} t_i$。我们用 $F(s, k, d; t_{max})$ 表示把一组 $op$ $(o_k, ..., o_K)$ 划分为 $s$ 个 stage 的最短总时延 —— 要求这些 stage 被放置到 $d$ 个 GPU 上,且每个 stage 的时延均不超过 $t_{max}$。则可以得到如下最优子结构:
$$ \begin{equation} \begin{split} F(s,k,d;t_{max}) &= \min_{k \leq i \leq K; n_s \cdot m_s \leq d} \Big\{ t_{intra} \big( (o_k, ..., o_i), Mesh(n_s, m_s), s) \big) \\ &+ F(s-1, i+1, d-n_s \cdot m_s; t_{max}) \\ &\mid t_{intra} \big( (o_k, ..., o_i), Mesh(n_s, m_s), s) \big) \leq t_{max} \Big\}. \end{split} \tag{e.q. 2} \end{equation} $$
这个最优子结构的含义是:我们要找到一个最优的分界点 $i$ 和一个大小为 $n_s \times m_s$ 的 device mesh,将 $op$ $(o_k, ..., o_i)$ 划分为一个 stage 并映射到上述 device mesh 上,且满足:
- device mesh 中 GPU 的个数不超过
$d$:$n_s \times m_s \leq d$; - 该 stage 的时延不超过
$t_{max}$。
对于每个 $t_{max}$,迭代的起点是 $F(0, K+1, 0; t_{max}) = 0$,终点则是
$$ \begin{equation} T^* (t_{max}) = \min_{s} \Big\{ F(s,0,N \cdot M; t_{max}) \Big\} + (B-1) \cdot t_{max}. \end{equation} $$
$B$ 作为 microbatch 的个数,是一个需要手动指定的超参数。注意,$t_{intra} \big( (o_k, ..., o_i), Mesh(n_s, m_s), s) \big)$ 是在 intra-$op$ parallelism 阶段通过整数线性规划来决定的,它的物理意义是将子图 $(o_k, ..., o_i)$ 映射到 $Mesh (n_s, m_s)$ 上的最小时延,该式要求子图 $(o_k, ..., o_i)$ 有 $s$ 个后继 stage。
从大小为 $N \times M$ 的二维平面上划分走一个大小为 $n_s \times m_s$ 的 mesh 15,毫无疑问,我们有很多个候选。选哪一个呢?Alpa 是这样做的:它从当前的平面上枚举了所有可能的 $Mesh (n_s, m_s)$,将这些 mesh 依次带入整数线性规划中进行求解,然后从满足如下要求的 mesh 中选择使得 $(o_k, ..., o_i)$ 延迟最小的那一个:
$$ \begin{equation} Mem_{(o_k, …, o_i),d} + s \cdot Mem_{act,d} \leq Mem_d, \forall d \in Mesh (n_s, m_s). \tag{e.q. 3} \end{equation} $$
$(\textrm{e.q. 3})$ 的含义是,对于 $Mesh (n_s, m_s)$ 中的每一个 GPU $d$,执行该 stage 所需的显存需求加上需要 cache 的中间数据的显存需求不得超过 $d$ 的显存总量。注意,不同的 stage 对 GPU 显存的需求其实有很大差异。越靠前的 stage,需要 cache 的中间数据越多 16。这一点也在 $(\textrm{e.q. 3})$ 中反映出来了。如果我们找不到满足要求的 $Mesh (n_s, m_s)$,则将 $t_{intra} \big( (o_k, ..., o_i), Mesh(n_s, m_s), s) \big)$ 设置为无穷大。这意味着当前的 $t_{max}$ 是不合适的,我们直接对下一个 $t_{max}$ 进行动态规划。
接下来,我们探讨一下上述动态规划的复杂度。首先我们需要枚举所有的 $t_{max}$,这意味着,我们需要 $(i)$ 枚举所有可能的 stage $(o_i, ..., o_j), \forall i,j=1, ..., K$;$(ii)$ 枚举所有的 device mesh。前者有 $K^2$ 个候选,后者有 $N + \log M$ 个候选(这是因为 device mesh 只允许有那两种结构)。因此,一共有 $\mathcal{O} (K^2 (N + \log M))$ 个 $t_{max}$。紧接着,对于每个 $t_{max}$,我们调用动态规划对其进行求解。观察 $F(\cdot, \cdot, \cdot; t_{max})$,可以发现,动态规划的复杂度为 $\mathcal{O} (K^3 N M (N + \log M))$。因此,整个 inter-$op$ parallelism 阶段的复杂度为 $\mathcal{O} (K^5 N M (N + \log M)^2)$。
显然,这个复杂度非常高。为了降低复杂度,Alpa 从如下两个方面进行了优化。
剪枝(Early Pruning)。 对于每一个 $t_{max}$,如果 $B \cdot t_{max} > T^*$,其中后者是到目前为止最优的 $T^*$,则直接选择下一个 $t_{max}$ 进行计算。此外,当前 $t_{max}$ 应满足 $t_{max} > (1+ \epsilon)T_{max}'$,其中 $t_{max}'$ 是上一轮的 $t_{max}$,否则也直接结束。这都是为了尽可能缩小需要进行动态规划的 $t_{max}$ 的数量。
$op$ 聚类(Operator Clustering)。 Alpa 将整个计算流图 $(o_1, ..., o_K)$ 聚类为 $L$ 个 layer $(l_1, ..., l_L)$,且 $L \ll K$,划分 stage 的基本单位变为 layer,而非 $op$。这样就极大地降低了复杂度。那么,要如何将相邻的 $op$ 聚为一个 layer 呢?我们用 $G(k,r)$ 表示把 $op$ $(o_1, ..., o_k)$ 聚类为 $r$ 个 layer 时,单个 layer 所接收的最大数据量的最小值,并且用 $C(i,k)$ 表示 $(o_i, ..., o_k)$ 从 $(o_1, ..., o_{i-1})$ 接收到的总数据量,则 $G(k,r)$ 的更新服从如下最优子结构:
$$ \begin{equation} \begin{split} G(k,r) = \min_{1 \leq i \leq k} \max \bigg\{ &G(i-1, r-1), C(i,k) \\ &\mid Flop(o_i, …, o_k) \leq \frac{(1+\delta) Flop_{total}}{L} \bigg\}, \end{split} \tag{e.q. 4} \end{equation} $$
其中 $Flop_{total} = Flop(o_1, ..., o_K)$ 是整个计算流图的 FLOPs。上述约束是为了确保每个 layer 分得的计算量不会超过全体计算量的均值太远。如果 $i$ 和 $j$($1\leq i,j \leq k$)均满足 $(\textrm{e.q. 4})$,则选择「使得每个 layer 分到的计算量更接近」的那一个。求解 $(\textrm{e.q. 4})$ 的复杂度为 $\mathcal{O} (K^2 L)$。和 $B$ 一样,$L$ 也是一个需要手动指定的超参数。
至此,Alpa 的工作原理阐述完毕。算法 1 给出了 Alpa 的工作流程。

其中,第 14 行 是在枚举所有大小为 $n \times m$ 的 device mesh,它对应于 $(\textrm{e.q. 3})$ 上方的文字描述;第 15 行是调用 solver 求解整数线性规划问题;第 17 行的 Eq. 5 对应本文中的 $(\textrm{e.q. 3})$。
不同的 stage 被分配给不同的 device mesh 之后,相邻的 stage 之间在传递数据时,必然会产生 resharding 的需求。作者将这种 communication 命名为 cross-mesh resharding。对此,Alpa 的解决方案是:前序 mesh 的各个 GPU 先分别将各自托管的 data partitions 发送给后继 mesh 中的某个 GPU;后继 mesh 再在内部通过 gather 等方式把完整的数据扩散给全体 GPU。作者将其称之为 local all-gather。
5 和 Whale 的对比
Whale 是 Alibaba 研发的一款用于分布式训练的框架,对应的工作 Whale: Efficient Giant Model Training over Heterogeneous GPUs. 发表在 ATC '22 上。类似地,Whale 允许将模型拆分成多个 stage,通过指定 microbatch 的个数,使得这些 stage 以流水线的方式执行。在每个 stage 内,Whale 提供了两个原语:replicate(device_count) 和 split(device_count)。它们以 context manager 的形式作用在各个 stage 上。Whale 的使用方式如图 12 所示:

replicate(device_count) 将对应的 stage 以 DP 的方式分散在 device_count 个 GPU 上。如果没有指定 device_count 的值,则该 stage 将被分发给每一个 GPU。此外,mini-batch 将会被切分成 device_count 份,每一个 replica 使用其中一份进行训练;split(device_count) 对应于 OP。它将对应的 stage 进行 intra-tensor sharding,sharding 的个数为 device_count,每个 sharding 放置在一个 GPU 上。图 13 给出了一种混合并行策略。

图 13 中的代码所描述的并行策略,我们将其可视化为图 14:
Whale 还支持模型的自动化并行,用户只需要提供数据流图的定义和 Whale 的全局参数设定即可:

显然,Whale 在开发设计阶段,会面临和 Alpa 一样的问题,包括但不限于:
- 每个 stage 应当被映射到哪些 GPU 上?怎样实现?
- stage 内部如何进行 sharding?
对于问题 1,Whale 引入了 VirtualDevice 的概念,它作为对物理 GPU 的一层抽象,负责将每个 stage 分发给具体的 GPU 执行。不妨设一共有 $K$ 个 GPU,每个 stage 的 device_count 依次为 $d_1, ..., D_N$,$N$ 是 stage 的个数。模型的每个 stage 在 replicate 或 split 的基础上,还会被整体实施一个 $\frac{K}{\sum_{i=1}^N d_i}$-degree 的 DP,从而充分提高模型训练的吞吐量。对于问题 2,Whale 引入了 ShardingUnit 和 ShardingInfo 的概念,它和 Alpa 中的 $X_i \in \{ R, S \}$ 相比,表达 sharding 模式的能力差一些,但 sharding 的决策空间也相应小得多。作者没有给出更多的描述,更多细节只能从代码中获得。
除了上述两个问题,Whale 充分考虑了 GPU 的异构性 —— 它认为 stage 内的各个 sharding/replica 之间都不应该分得相同的 workload,而应当根据所在 GPU 的算力按比例分配。具体地,对于任意一个 stage,不妨设它的各个部分(sharding, or replica)被分发到 $N$ 个 GPU 上。我们用 $L_i$ 表示第 $i$ 个 GPU 分得的 load ratio 17,它通过求解如下问题来决定:
$$ \begin{equation} \begin{split} &\min_{L_i} \sum_{i=1}^N \Big| L_i - \frac{DF_i}{\sum_{i=1}^N} DF_i \Big| \\ s.t. \sum_{i=1}^L &L_i = 1, L_i \times TG_{mem} \leq DM_i, \forall i. \end{split} \tag{e.q. 5} \end{equation} $$
其中,$DF_i$ 和 $DM_i$ 分别是 GPU $i$ 的浮点运算性能和显存大小,$TG_{mem}$ 则是该 stage 请求的显存大小。
此外,不同的 stage 因为对显存的需求不一致(如前文所述,越靠前,需求越大),所以 Whale 将 GPU 按照显存从大到小排列之后,依次分给每个 stage。
以上便是 Whale 大致的工作原理。对比 Whale 和 Alpa,我们可以发现:
- Whale 的核心贡献主要在于该分布式训练框架的研发,但缺少足够的优化,较多地方采用简单的 heuristic 进行实现;
- Alpa 对不同的并行充分进行了优化,但是其 formulation 存在改进空间。
最后
本文讨论了 Alpa 的工作原理,深入介绍了其 intra-$op$ parallelism 和 inter-$op$ parallelism 两个阶段的细节。在 intra-$op$ parallelism 阶段,Alpa 通过建立一个整数线性规划来求解给定子图和 device mesh 下的最优 sharding 方案;在 inter-$op$ parallelism 阶段,Alpa 通过动态规划来确定一个模型应当被划分为多少个 stage、每个 stage 应当被映射到哪个 device mesh 上。Alpa 存在较大的改进空间,包括但不限于问题的 formulation、算法的的复杂度等。此外,一些技术也可以和 Alpa 结合,例如:communication compression/censoring、mixed/low-precision training、memory optimization 等。
图 1、3、5、6、10,表 1、2、3,以及算法 1 来自 Alpa 论文;图 2、图 11 分别来自以下论文:
- Jiang, Yimin, et al. A unified architecture for accelerating distributed DNN training in heterogeneous GPU/CPU clusters. In OSDI '20.
- Huang, Yanping, et al. Gpipe: Efficient training of giant neural networks using pipeline parallelism. In NeuIPS '19.
图 4、12-15 来自 Whale 论文。
转载申请

本作品采用 知识共享署名 4.0 国际许可协议 进行许可,转载时请注明原文链接。您必须给出适当的署名,并标明是否对本文作了修改。
-
反向传播的数学原理可以参考 反向传播的数学原理 · 深度学习 05。 ↩︎
-
显然,这里有很大的可改进空间。如果选取同步的策略,averaging 只有在最慢的 worker(计算 + 通信开销)将数据传递过来之后才能进行。因此,有一些工作从理论上探索了异步 averaging 的性能。还有一些工作从 partial update 的角度出发进行分析,即每一轮 PS 只需要收集到来自部分 worker 的参数更新即可。这些理论工作通常和分布式优化(Distributed Optimization)这一研究方向紧密关联,目前一种叫做 ADMM 的数值优化算法被广泛运用。读者可以阅读 Everything about ADMM 获取关于 ADMM 的更多信息。 ↩︎
-
如果参与该算子运算的 GPU 都是同构的,这样的划分就是最优的。 ↩︎
-
Xu, Yuanzhong, et al. Automatic cross-replica sharding of weight update in data-parallel training. arXiv preprint arXiv:2004.13336, 2020. ↩︎
-
Alpa 对全体的 GPU 做了一个 disjoint 划分,得到一系列的 GPU 组。这一点会在后文阐述。 ↩︎
-
子问题 2 可以描述为:将一群 GPU 划分成一组互不相交的子集,每个子集以 mesh 的形式排列,请枚举所有的划分方案。「枚举」显然是不现实的。为了简化问题,Alpa 的作者只考虑如下两种形式的 mesh —— 第一种(one-dimensional):
$(1,1), (1,2), ..., (1, 2^m)$;第二种(two-dimensional):$(2, M), (3, M), ..., (N, M)$。我会在第四章深入介绍这一点。 ↩︎ -
这个优化目标似乎可以改进。考虑到
$G$中的$op$在执行时可能存在 overlapping(不同$op$的计算 / 通信之间的 overlapping、一个$op$内部边计算边通信等),这个优化目标并不能反映出$G$的 makespan。 ↩︎ -
毫无疑问,这个工作量大得离谱。 ↩︎
-
这样可以减少求解规划问题的时间。 ↩︎
-
这里其实暗含了一个假设,即模型服从
$o_1 \to o_2 \to ... \to o_K$这样的线性结构。Alpa 直接从数据流图的定义代码中抽取。 ↩︎ -
Huang, Yanping, et al. Gpipe: Efficient training of giant neural networks using pipeline parallelism. In NeuIPS '19. ↩︎
-
这里的表述不够严谨。这个二维平面可能已经是 “残缺不全” 的了 —— 之前的迭代已经划走了一部分 GPU。 ↩︎
-
第
$i$个 stage,需要缓存$S-i$个前向传播的输出。注意,$(\textrm{e.q. 3})$中$s$就等于$S-i$。这个技术叫做 weight staging,由 PipeDream 论文提出:Narayanan, Deepak, et al. Pipedream: generalized pipeline parallelism for dnn training. In SOSP '19. ↩︎ -
如果是 replicate,则 load ratio 代表每个 GPU 分得的部分 batch size 的占比;如果是 split,则 load ratio 代表每个 GPU 分得的 sharding 的 ratio。 ↩︎