树和图是十分重要的数据结构。在树和图上的操作(如层序遍历、深度优先遍历、寻找最短路、给出拓扑排序、判断是否连通等)在大型工程项目中频繁出现。在前一篇文章中我们分析了树和二叉树的建立、BFS 和 DFS。本文将会以同样的风格对图的相关操作代码进行分析。
图(graph)描述的是一些个体之间的关系,这些个体之间既不是前驱后继的顺序关系,也不是祖先后代的层次关系,而是错综复杂的网络关系。
1 图上的常见问题
1.1 深度优先遍历
和树一样,图上也有深度优先遍历(DFS),并且也用递归来实现。最典型的、图上的 DFS 的应用案例是「求连通块」。
例题 1:油田(Oil deposits, UVa 572)
输入一个 $m$ 行 $n$ 列的字符矩阵,统计字符 @ 组成了多少个八连块。如果两个字符 @ 所在的格子相邻(横、竖或者对角线方向),就说它们属于同一个八连块。
样例输入:
5 5
****@
*@@*@
*@**@
@@@*@
@@**@
样例输出:2
如果我们把 @ 看成节点,相邻的 @ 看成节点之间的无向边,则本题就是要找到输入中的连通图的个数。对于输入的二维字符数组中的任意一个位置 (r,c),如果这个位置存放的是 @ 且没有被访问过,则它属于某个连通块。但是,它属于哪一个连通块呢?因此,我们需要给连通块编号。假设这个元素属于连通块 $x$,则我们递归探索它周遭的 8 个位置,只要这些位置没有被访问过且存放的是 @,那么它们也属于连通块 $x$。否则,直接退出,返回到调用者。
基于以上分析,我们可以写出如下代码:
const int maxn = 100 + 5;
char arr[maxn][maxn]; // 存放读入的二维数组
int m, n; // 字符矩阵的真实大小
int idx[maxn][maxn]; // 存放每个位置的元素所属的连通图的编号
void dfs(int r, int c, int cnt) {
if (r < 0 || r >= m || c < 0 || c >= n) return; // 出界
if (idx[r][c] != 0 || arr[r][c] != '@') return; // 已被探索或不是 @
idx[r][c] = cnt;
for (int dr = -1; dr <= 1; dr++) {
for (int dc = -1; dc <= 1; dc++) {
if (!(dr == 0 && dc == 0)) {
dfs(r + dr, c + dc, cnt); // 递归
}
}
}
}
我们在主函数中启动对 dfs() 的调用:
int main() {
// do sth...
int cnt = 0;
memset(idx, 0, sizeof(idx));
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (arr[i][j] == '@' && idx[i][j] == 0) {
dfs(i, j, ++cnt);
}
}
}
// do sth...
}
主函数中调用 dfs() 的这一行被执行的次数就是连通块的个数。
完整代码请参见 aoapc/ch06/e6-12。
这份代码极为重要,必须要彻底掌握。
1.2 广度优先遍历
和树一样,图上也有广度优先遍历(BFS),也借助队列来实现。在二叉树的 BFS 中,节点的访问顺序恰好是它们到根节点距离从小到大的顺序。 类似地,图上的 BFS 可以用于求出最短路径。
考虑如下问题:给出一个二维单元格组成的网格,每个单元格要么是空地(用 1 来表示),要么是障碍物(用 0)来表示,给定起点和终点,如何求出从起点到终点的最短路径?假设起点在左上角,则我们从左上角开始遍历迷宫,逐步计算出它到每一个节点的最短距离,结果如图 1 所示。

我们仍然借助队列来实现:
const int maxn = 200 + 5;
int arr[maxn][maxn]; // 存放迷宫
int dis[maxn][maxn]; // 存放各单元格到起点的最短距离
int c[maxn][maxn]; // 存放 BFS 树中各个节点的编号
int m, n; // 迷宫大小
struct Node {
int x, y;
Node(int x = 0, int y = 0) : x(x), y(y) {}
};
Node parent[maxn][maxn];
// 四个遍历方向
int dr[] = {-1, 1, 0, 0};
int dc[] = {0, 0, -1, 1};
void bfs() {
queue<Node> q;
memset(dis, -1, sizeof(dis));
memset(c, 0, sizeof(c));
int cnt = 1;
Node u(0, 0); // 起点
dis[0][0] = 0;
c[0][0] = cnt;
q.push(u);
while (!q.empty()) {
Node v = q.front();
q.pop();
int i = v.x, j = v.y;
// 探索周遭的四个单元格
for (int k = 0; k < 4; k++) {
int i2 = v.x + dr[k], j2 = v.y + dc[k];
// 这个单元格位置合法、不是障碍物且没有被访问过
if (i2 >= 0 && i2 < m && j2 >= 0 && j2 < n && arr[i2][j2] == 1 && dis[i2][j2] < 0) {
dis[i2][j2] = dis[i][j] + 1; // 更新最短距离
parent[i2][j2] = v; // 设定指向父亲的指针
c[i2][j2] = ++cnt; // 设定本节点的编号
q.push(Node(i2, j2));
}
}
}
}
在上面的代码中,我们用二维数组 parent 记录每个单元格(视为一个节点)的「从起点到它的最短路径」中的父节点。二维数组 c 则记录了扩展顺序。如图 2 所示,如果我们把箭头视为「指向父亲的指针」,则这些单元格就变成了一棵树,我们称之为最短路树(a.k.a. BFS 树)。
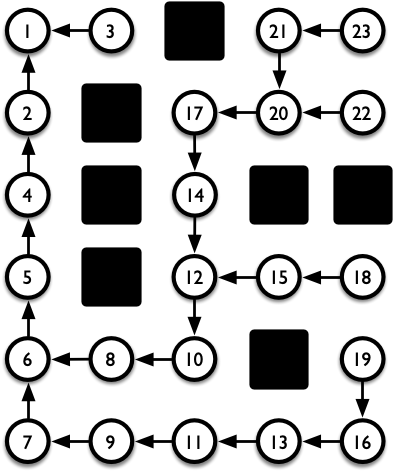
我们将这棵 BFS 树展开,如图 3 所示。
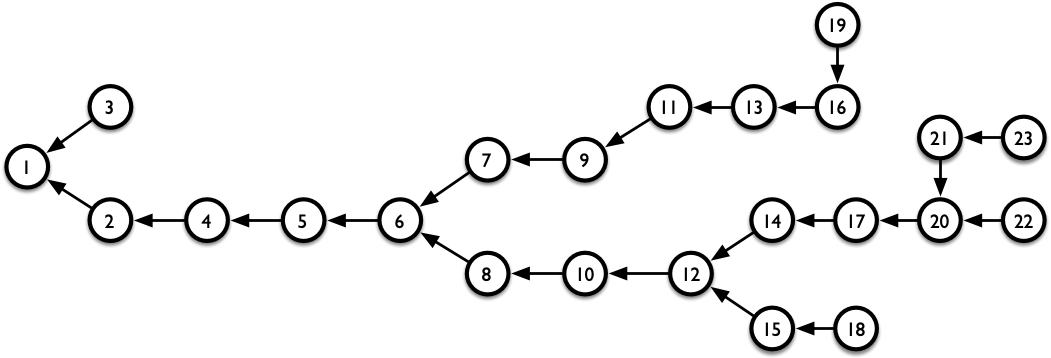
最后,我们给出起点到任意点 $(x,y)$ 的最短路径的输出函数。在这个函数中,我们用 vector 保存最短路径途径的节点,然后逆序输出。
// 追溯从初始节点到目标节点 Node(x,y) 的最短路径
// 用 vector 保存路径并且倒序输出
void print_path(Node u) {
vector<Node> path;
for (;;) {
path.push_back(u);
if (dis[u.x][u.y] == 0) break; // 到达起点
u = parent[u.x][u.y]; // 找到父亲节点
}
for (int i = path.size() - 1; i >= 0; i--) {
printf("(%d,%d)", path[i].x, path[i].y);
}
printf("\n");
}
完整代码请参见 aoapc/ch06/c6-14。大多数「在迷宫中寻找最短路径」问题的求解方法和上面的代码一致。直接的扩展例题有
- Abbott 的复仇(Abbott’s revenge, ACM/ICPC World Finals 2000, UVa 816);
- 骑士的移动(Knight moves, UVa 439);
- 巡逻机器人(Patrol robot, ACM/ICPC Hanoi 2006, UVa 1600);
在第一题和第二题中,我们需要自定义每一步(方向、步长);在第一题和第三题中,vis 矩阵需要增加一个维度,因为这两道题中,每经过一步所抵达的新状态仅仅用坐标 $(x,y)$ 来描述是不够的。这三题的求解代码请分别参见 aoapc/ch06/e6-14、aoapc/ch06/p6-4 和 aoapc/ch06/p6-5。
1.3 拓扑排序
对于一个有向图,如果我们将每个节点进行排序,使得每一条有向边 $(u,v)$ 对应的节点 $u$ 都排在节点 $v$ 的前面,则称这个排序为 拓扑排序。显然,如果图中存在环路,则不存在拓扑排序;反之则存在。我们将不存在环路的有向图称为 有向无环图(DAG)。 对于一个给定的 DAG,拓扑排序可以有多个。对于图 4 所示的 DAG,「1 5 4 6 2 3」、「1 4 6 5 2 3」、「1 4 6 2 5 3」等都是合法的拓扑排序。
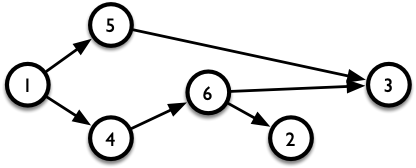
现在的问题是,如何求出 DAG 的拓扑排序?或者说,我们应该使用 DFS 还是 BFS?沿着一条路径往下走得「足够深」,我们才能判断这条路径是否回到起点——即形成环路。我们总应该探索出一条完整的路径出来,因此应该使用 DFS。可是,要怎么做呢?可以发现,对于任意一个节点 $u$,它有三种可能的访问状态:
- 这个节点尚未被访问过(记为 0);
- 这个节点已经被访问过,并且它的所有子孙节点也都被递归访问过(记为 1);
- 这个节点正在被访问(它正在被访问或者它的子孙节点正在被访问),递归调用栈尚未退出(记为 -1)。
当我们使用 DFS 时,每当访问完一个节点,就应当把它插入到当前拓扑顺序的 首部。这是因为我们的递归调用总是先递归到「最深处」,即最末端的孩子节点是先被记录下来的——它自然应该被记录在队伍的末尾。我们只要不断在首部插入,就能保证这是一个「从父亲到孩子」的顺序。
基于以上分析,dfs() 函数可以被实现如下:
const int maxn = 200 + 5;
int vis[maxn]; // 存放访问状态
int topo[maxn]; // 存放拓扑排序
int G[maxn][maxn]; // G[u][v] = 1 若存在从 u 到 v 的边
int n; // 节点个数
int t; // 游标,总是指向当前拓扑排序的首部
bool dfs(int u) {
vis[u] = -1;
for (int v = 0; v < n; i++) {
if (G[u][v]) {
if (vis[v] < 0) { // v 正在被访问,说明有环路
return false;
} else if (!vis[v] && !dfs(v)) { // v 没有被访问过,但是从它开始访问发现有环路
return false;
}
}
}
// 递归访问结束,登记到拓扑排序中
vis[u] = 1;
topo[--t] = u;
return true;
}
我们在主函数中启动对 dfs() 的调用:
int main() {
// do sth...
t = n;
memset(vis, 0, sizeof(vis));
for (int u = 0; u < n; u++) {
if (!vis[u]) {
if (!dfs(u)) {
printf("Loop exists.\n");
return 0;
}
}
}
for (int i = 0; i < n; i++) {
printf("%d", topo[i]);
}
// do sth...
}
可以用拓扑排序解决的问题有 给任务排序(Ordering tasks, UVa 10305),对应的求解代码参见 aoapc/ch06/e6-15,此处不在展开。
1.4 欧拉道路与欧拉回路
欧拉道路的概念源自著名的「七桥问题」。其本质是,能否从无向图中的一个节点出发走一条道路,使得每条边恰好经过一次。这样的道路被称为「欧拉道路」(Eulerian Path)。为了保证每条边恰好被走一次,则必然有如下结论:除了起点和终点,其他点的进出次数相等。即,除了起点和终点,其他点的度数为偶数。下面直接给出无向图中欧拉道路存在的充分条件。
无向图中欧拉道路存在的充分条件(结论)。 如果一个无向图是连通的,且最多只有两个奇点,则一定存在欧拉道路。- 如果不存在奇点,则可以从任意点出发走出一条欧拉道路,最终会回到该点(形成了欧拉回路);
- 如果有两个奇点,则必须从其中一个奇点出发,抵达另一个奇点。
同样地,我们直接给出有向图中欧拉道路存在的充分条件:
有向图中欧拉道路存在的充分条件(结论)。 如果一个有向图在忽略边的方向之后是连通的,且最多只能有两个节点的入度不等于出度,而且必须是其中一个节点的出度比入度大 1(作为起点),另一个节点的入度比出度大 1(作为终点),则该有向图中存在欧拉道路。综上所述,我们将计算欧拉道路的套路总结如下:
- 判断无向图(或有向图的底图)是否是连通的,可以采用例题 1 中给出的「计算连通块」的 DFS 方法,也可以采用「并查集」方法;
- 基于 DFS 计算欧拉道路。代码如下面所示。
对于无向图,下面的代码给出了欧拉道路(回路)的计算:
const int maxn = 100 + 5;
int G[maxn][maxn];
int vis[maxn][maxn];
int n;
struct Edge {
int x, y; // 一条边用节点 (x,y) 来标识
Edge(int x = 0, int y = 0) : x(x), y(y) {}
};
stack<Edge> euler_path;
// 无向图中求欧拉道路的 DFS(已经确定 G 形成了连通图)
void dfs(int u) {
for (int v = 0; v < n; v++) {
if (G[u][v] && !vis[u][v]) {
vis[u][v] = vis[v][u] = 1;
dfs(v);
euler_path.push(Edge(u, v));
}
}
}
对于有向图,我们只需要将 vis 数组的设定这一行稍加修改即可:
// 有向图中求欧拉道路的 DFS(已经确定 G 形成了连通图)
void dfs(int u) {
for (int v = 0; v < n; v++) {
if (G[u][v] && !vis[u][v]) {
vis[u][v] = 1;
dfs(v);
euler_path.push(Edge(u, v));
}
}
}
关于欧拉道路的一个完整代码示例参见 aoapc/ch06/c6-16。在这个示例中,我们手动构造了一个连通图,然后将欧拉道路中打印出来。
1.5 将问题化归为图问题
到目前为止,我们讲述了图上的「广度优先遍历及其应用(求最短路径)」和「深度优先遍历及其应用(求连通块的个数、求拓扑排序和求欧拉回路)」。然而,在实际情况中,图常常是隐藏在问题的描述中的,将它们化归成图问题,需要一定的思维能力。接下来将结合几道题目阐述如何将实际问题化归成图问题。
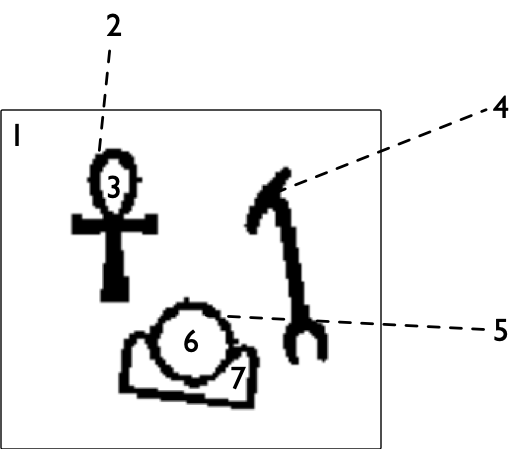
例题 2:古代象形符号(Ancient messages, ACM/ICPC World Finals 2011, UVa 1103)
本题的目的是识别 3000 年前古埃用到的 6 个象形文字,如图 5 所示。输入的是一个 $H$ 行 $W$ 列的字符矩阵,每个字符为横着连续的 4 个相邻像素点的十六进制(例如,10011100 对应的字符是 9c)。每个像素点要么为 1(表示黑点)、要么为 0(表示白点)。输入的二维字符矩阵满足:
- 每个黑像素都属于一个符号;
- 不同符号不会相互接触,也不会相互包含;
- 符号的形状一定和图 5 所示的图形拓扑等价。
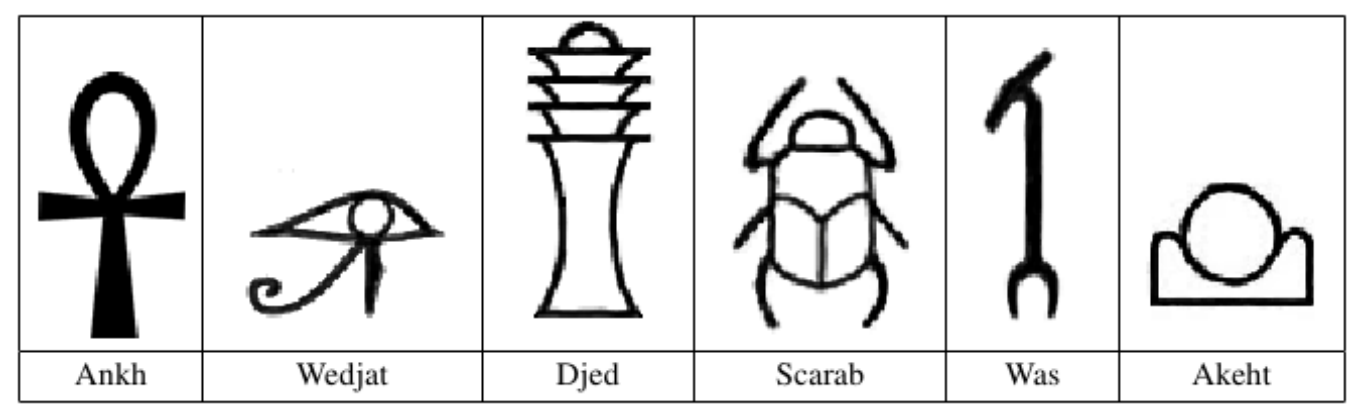
我们需要按照字典序输出字符矩阵中识别出的所有符号。
图 6 给出了两个样例输入,对于第一个输入,我们需要输出 AKW;对于第二个输入,我们需要输出 AAAAA。

可以发现,二维矩阵中的每个符号组成了一个连通块(图)。由于题目规避了不同字符的重叠和接触,因此连通块的个数就是符号的个数。我们可以先通过 DFS 求出字符的个数。可是,要如何识别出每个连通块分别是 6 个字符中的哪一个呢?显然,我们需要利用「拓扑等价」这个特性。仔细观察图 5,可以发现,我们可以用每个字符内部的白色连通块的个数来区分这 6 个字符(分别为 1、3、5、4、0、2 个)。
可是,如何量化「内部」?一种方法是,直接求出所有连通的部分。如图 7 所示,我们可以在第一个样例输入中找到 7 个连通部分,其中,编号为 1 的是白色背景(字符外部),编号为 2、4、5 的,分别是 3 个字符,编号为 3 的是第一个字符内部的白色连通块,编号为 6 和 7 的,均是第三个字符内部的白色连通块。我们只需要通过和例题 1 中的 dfs() 类似的代码即可找到全部的连通部分。与此同时,我们需要识别出编号为 2、4、5 的连通块代表字符,并将它们的非白色背景的邻居存储下来。例如,第一个字符的内部邻居有 1 个,为 3;第三个字符的内部邻居有 2 个,为 6、7。这样,我们就可以将这些字符和图 5 所示字符对应起来了。最后按照字母顺序输出即可。
在给出 dfs() 之前,我们还有一些事情要做,那就是将输入的字符矩阵转换为 01 矩阵。
// 01 矩阵的最大大小
const int max_height = 200 + 5;
const int max_width = 50 * 4 + 5;
// pic 存放 01 矩阵
int pic[max_height][max_width];
// 01 矩阵的实际大小
int H, W;
// 存放每一个十六进制的字符到二进制串的映射
// 第一维度之所以是 256,是因为我们直接用 char 隐式转换为 int 作为 index,而 ASCII 码中有 256 个字符。
char hex2bin[256][5];
// 存放每一行读入的十六进制字符串
char line[max_width];
void set_hex2bin() {
strcpy(hex2bin['0'], "0000");
strcpy(hex2bin['1'], "0001");
strcpy(hex2bin['2'], "0010");
strcpy(hex2bin['3'], "0011");
strcpy(hex2bin['4'], "0100");
strcpy(hex2bin['5'], "0101");
strcpy(hex2bin['6'], "0110");
strcpy(hex2bin['7'], "0111");
strcpy(hex2bin['8'], "1000");
strcpy(hex2bin['9'], "1001");
strcpy(hex2bin['a'], "1010");
strcpy(hex2bin['b'], "1011");
strcpy(hex2bin['c'], "1100");
strcpy(hex2bin['d'], "1101");
strcpy(hex2bin['e'], "1110");
strcpy(hex2bin['f'], "1111");
}
// 将输入的十六进制矩阵转换为 01 矩阵存入 pic
void decode(char ch, int r, int c) {
for (int i = 0; i < 4; i++) {
pic[r][c + i] = hex2bin[ch][i] - '0';
}
}
int main() {
set_hex2bin();
while (scanf("%d%d", &H, &W) == 2 && H) {
// 读取十六进制矩阵转换为 01 矩阵存入 pic 中
memset(pic, 0, sizeof(pic));
for (int i = 0; i < H; i++) {
scanf("%s", line);
for (int j = 0; j < W; j++) {
// 注意!这里字符从位置 (1,1) 开始写入
decode(line[j], i + 1, j * 4 + 1);
}
}
// 后续处理逻辑...
}
}
上面的代码使用 set_hex2bin() 和 decode() 函数实现字符数组到 01 矩阵的转换。
接下来,我们给出 dfs() 求出 01 矩阵中的所有连通块。这部分代码和例题 1 类似。
int idx[max_height][max_wdith];
// 这两个数组组合起来用于遍历一个位置上下左右的四个位置
const int dr[] = {-1, 1, 0, 0};
const int dc[] = {0, 0, -1, 1};
void dfs(int r, int c, int cnt) {
idx[r][c] = cnt;
for (int i = 0; i < 4; i++) {
int r2 = r + dr[i];
int c2 = c + dc[i];
// dfs 的条件 —— 位置 (r2, c2) 合法、该位置没有被探索过、且该位置和 (r, c) 数字一致(要么同为 0、要么同为 1)
// 满足这 3 个条件的位置才和本位置属于同一个连通块
if (r2 >= 1 && r2 <= H && c2 >= 1 && c2 <= 4 * W && pic[r][c] == pic[r2][c2] && idx[r2][c2] == 0) {
dfs(r2, c2, cnt);
}
}
}
同样地,我们在主函数中调用 dfs():
int main() {
set_hex2bin();
while (scanf("%d%d", &H, &W) == 2 && H) {
// 读取十六进制矩阵转换为 01 矩阵存入 pic 中...
int cnt = 0;
// cc 存放了符号(黑色线条)的颜色编号,cc 的大小等于 pic 中字符的个数
// 以图 7 为例,cc 中存放的将会是 2、4、5
vector<int> cc;
memset(idx, 0, sizeof(idx));
for (int i = 1; i <= H; i++) {
for (int j = 1; j <= 4 * W; j++) {
if (!idx[i][j]) {
dfs(i, j, ++cnt);
if (pic[i][j] == 1) {
cc.push_back(cnt);
}
}
}
}
// 后续处理逻辑...
}
}
最后,我们需要找到 cc 中每个字符的内部邻居(白色连通块)。
// neighbors 是一个 vector,大小为输入的 pic 中不同的连通块的个数
// 对于每个连通块,用一个 set 记录与其接壤(相邻)的内部白色连通块的个数
vector<set<int>> neighbors;
// 按照白色洞(连通块)的个数来排序(0-5)6 个象形文字
const char *code = "WAKJSD";
int main() {
set_hex2bin();
while (scanf("%d%d", &H, &W) == 2 && H) {
// 读取十六进制矩阵转换为 01 矩阵存入 pic 中...
// 调用 dfs 计算连通块...
// 找到 cc 中每个字符的内部邻居(白色连通块)
neighbors.clear();
neighbors.resize(cnt + 1);
for (int i = 1; i <= H; i++) {
for (int j = 1; j <= 4 * W; j++) {
if (pic[i][j] == 1) {
// 对于每一个黑线(黑线连在一起组成一个符号),判断它的邻居
for (int k = 0; k < 4; k++) {
int r2 = i + dr[k];
int c2 = j + dc[k];
// idx 的编号为 1 意味这这个位置属于背景板,与我们要找的白色洞没有关系。因此要去掉
if (r2 >= 1 && r2 <= H && c2 >= 1 && c2 <= 4 * W && pic[r2][c2] == 0 && idx[r2][c2] != 1) {
// 以图 7 为例,有
// neighbors[element = 2] = {3}
// neighbors[element = 4] = {}
// neighbors[element = 5] = {6, 7}
// 注意,neighbours 内部的元素为 set,因此,当同一个颜色被重复插入时,不会改变 set 的大小和内容。
neighbors[idx[i][j]].insert(idx[r2][c2]);
}
}
}
}
}
// 后续处理逻辑...
}
}
到目前为止,我们已经将每个字符的内部白色连通块编号存入 neighbors 中了。接下来只需要和题目中的 6 个象形符号对比即可确定 cc 中每个数字对应的是哪一个字符了。
int main() {
set_hex2bin();
while (scanf("%d%d", &H, &W) == 2 && H) {
// 读取十六进制矩阵转换为 01 矩阵存入 pic 中...
// 调用 dfs 计算连通块...
// 找到 cc 中每个字符的内部邻居(白色连通块)...
// 用白色洞的个数来决定它属于哪一个符号,然后按照字母顺序输出
vector<char> ans;
for (int i : cc) {
int white_block_num = (int) neighbors[i].size();
ans.push_back(code[white_block_num]);
}
// 将识别出来的字符按照字母表顺序排序输出
sort(ans.begin(), ans.end());
}
}
最后将 ans 内的元素输出即可。看起来很完美。但是,这样真的完全正确吗?设想,如果 01 矩阵 pic 中左上角 (1,1) 的位置是一个黑像素,会发生什么?会导致编号为 1 的连通块是某个字符,而非白色背景!这就和我们所设想的、图 7 中给出的编号不一样了。这会导致 neighbors 计算错误,从而错解。一种简单的方法是将 01 矩阵向外扩展一圈(上下左右各加上一行一列空白像素 0),将检索区间从 (1,1) 到 (H,4*W) 变成 (0,0) 到 (H+1,4*W+1)。经过这个操作,我们可以保证编号为 1 的连通块一定是白色背景。
本题的完整代码请参见 aoapc/ch06/e6-13。
例题 3:单词(Play on words, UVa 10129)
输入 $n$ 个单词,判断是否可以将这些单词排成一个序列,使得每个单词的第一个字母和上一个单词的最后一个字母相同。每个单词均由小写字母组成,输入中可能有重复单词。
如果我们把一个单词的首字母和末尾字母看成节点,并且二者直接存在一条有向边,则原问题等价于判断有向图中是否存在欧拉道路(回路)。 根据前文的叙述,首先,我们需要判断有向图的底图是否是连通的;然后,我们计算每个节点的入度和出度并判断是否符合要求。
我们采用 DFS 判断底图是否是连通的:
int used[256]; // used[ch] = 1 表示这个字母是有向图的一个节点
int G[256][256]; // 是否存在边
int vis[256]; // 是否访问过
void dfs(int ch, int cnt) {
if (vis[ch] != 0 || !used[ch]) return;
vis[ch] = 1;
for (int ch2 = 'a'; ch2 <= 'z'; ch2++) {
if (used[ch2] && G[ch][ch2]) {
dfs(ch2, cnt);
}
}
}
和例题 1 类似,我们在主函数需要启动对 dfs() 的调用:
int main() {
// do sth...
// 使用 dfs 判断是否连通
int cnt = 0;
// 经过递归之后,若 cnt 等于 1,说明只有一个连通块,即是一个连通图
for (int ch = 'a'; ch <= 'z'; ch++) {
if (!vis[ch] && used[ch]) {
dfs(ch, ++cnt);
}
}
// do sth...
}
只要 cnt 的值为 1,就说明所有节点形成了一个连通图。
接下来,我们需要判断欧拉道路存在性的第二个条件。
int degree[256]; // 出度 +1,入度 -1
int main() {
// do sth...
// 假设 degree 在读取单词时已经按照如下方式设置:
// 每当遇到一条从 ch 出去的边,则 degree[ch]++;
// 每当遇到一条到 ch 的边,则 degree[ch]--
vector<int> d;
for (int ch = 'a'; ch <= 'z'; ch++) {
if (degree[ch] != 0) {
d.push_back(degree[ch]);
}
}
bool ok = false;
// cnt = 1 意味着可以形成一个连通块。这是欧拉道路存在的第一个条件
// 入度不等于出度的节点,要么是 0,要么是 2。若是 2,则必然一个出度 = 入度 + 1,另一个入度 = 出度 + 1。这是第二个条件
if (cnt == 1 && (d.empty() || (d.size() == 2 && (d[0] == 1 || d[0] == -1)))) ok = true;
if (ok) printf("Ordering is possible.\n");
else printf("The door cannot be opened.\n");
// do sth...
}
在本题中,我们利用了欧拉道路存在性定理进行判定。我们不需要打印出整条欧拉道路。完整代码请参见 aoapc/ch06/e6-16-2。
例题 4:自组合(Self-assembly, ACM/ICPC World Finals 2013, UVa 1572)
有 $n$ 种边上带标号的正方形。每条边上的标号要么是一个大写字母后面跟着一个加号或一个减号,要么为数字 00。当且仅当两个边的字母相同且符号相反时,这两条边能拼接在一起(00 边不能和任何边拼接在一起)。假设输入的每种正方形都有无数种,而且可以旋转和翻转,问:这些正方形能否拼接一个无限大的结构?
图 8 左边给出了 3 种正方形,右边是它们拼接而成的一个有限大的正方形。
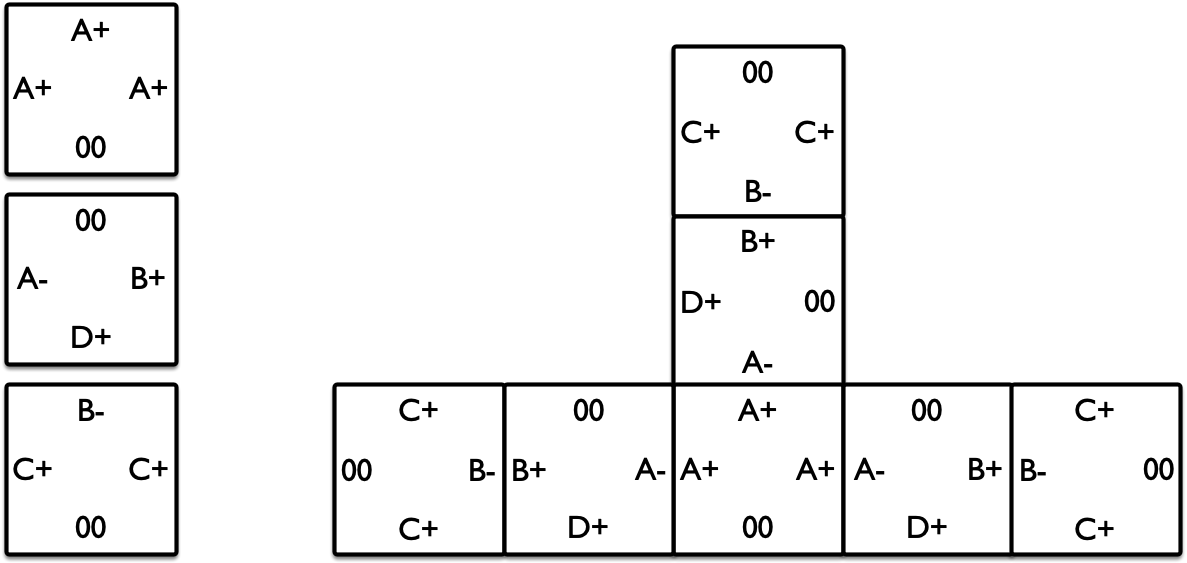
样例输入:
3
A+00A+A+ 00B+D+A- B-C+00C+
样例输出:bounded
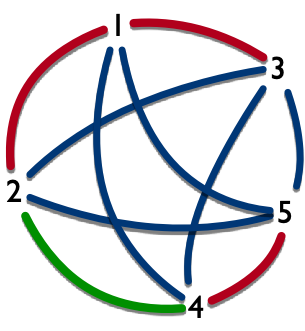
如何理解「形成无限大的结构」?无限大,并不一定要铺满整个平面,只要 能沿着一个方向不断延伸下去 也可以。正方形的拼接,就是将满足特定条件的边进行连接。如果我们将边上的标号看成图的节点,则对于图 8 左侧所示的第一个正方形,由于 $A+$ 可以和第二个正方形的 $A-$ 进行连接,这意味着 $A+$ 可以和第二个正方形非 $A-$、非 $00$ 的边进行 “连接”,即 分别存在一条「从 $A+$ 到 $B+$」和一条「从 $A+$ 到 $D+$」的边。同理,存在一条「从 $B+$ 到 $C+$」的边、一条「从 $B-$ 到 $A-$」的边和一条「从 $B-$ 到 $D+$」的边。也就是说,对于图 8 给出的案例输入,我们可以形成一个如图 9 所示的有向图:
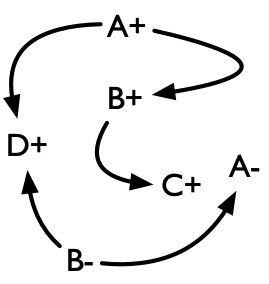
则能否延伸出一条无限长的通路,等价于边的标号形成的有向图中是否有环路。当存在环路时,这些标号所在的正方形就可以无限拼接下去。至此,我们将原问题化归为在有向图中判断是否存在环路的问题。我们可以对图执行一次拓扑排序,如果拓扑排序不存在,则意味着存在环路。因此,对于本题的求解,我们需要依次执行如下两个步骤:
- 按照如下规则建立有向图:把标号看成节点,正方形看成边,如果一个节点和另一个正方形的一个节点可以拼接的话,那么可以看成「这个节点和另一个正方形的剩下三个节点之间有有向边」;
- 在形成的有向图中通过拓扑排序的代码判断是否形成了环路。
整个实现没有什么难点,代码请参见 aoapc/ch06/e6-19。
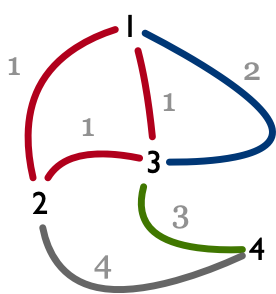
例题 5:理想路径(Ideal path, ACM/ICPC NEERC 2010, UVa 1599)
给一个 $n$ 个点、$m$ 条边组成的无向图,每条边上都涂有一种颜色。求节点 $1$ 到节点 $n$ 的一条路径,使得经过的边数尽可能少,在此前提下,经过边的颜色序列的字典序最小。注意,一对节点间可能有多条边。输入保证节点 $1$ 可达节点 $n$。输入第一行分别为节点和边的个数,从第二个开始,依次输入每条边的颜色。输出所求路径中边的个数,并按照顺序打印每条边的颜色。
样例输入:
4 6
1 2 1
1 3 2
3 4 3
2 3 1
2 4 4
3 1 1
样例输出:
2
1 3
对于上面的输入样例,其形成的图如图 10 所示。本题的核心诉求是求最短路径,但是难点在于「按颜色序例字典序最小」的方式给出最短路径。
在章节 1.2 中,我们使用 BFS tree 记录每个节点的父节点,在此处将不受用,因为 BFS tree 给出的路径并不能保证字典序最小。实际上,无需记录父节点也可以得到最短路,方法是从终点开始 “倒着” BFS,得到每个节点 $i$ 到终点的最短距离 dis[i]。然后,直接从起点开始走,每到达一个新节点时要保证距离值恰好减 1。如果有多个候选节点满足这个条件,则选择使得颜色字典序最小的节点;如果存在多个候选节点都能使得颜色字典序最小,则记录全部这些节点作为下一步的候选。如此操作,直到抵达终点。我们一共做了两次 BFS。
我们首先准备好所需要的基础变量和结构体:
const int maxn = 100000 + 5; // 最大节点个数
const int maxc = 1000000000; // 最大颜色个数
int n; // 节点个数
bool vis[maxn]; // 访问标记
int dis[maxn]; // 每个节点到终点的最短距离
struct Edge {
int u, v, c;
Edge(int u = 0, int v = 0, int c = 0) : u(u), v(v), c(c) {}
};
vector<Edge> edges;
vector<int> G[maxn]; // G[u] 记录了和 u 相连的边的索引
void add_edge(int u, int v, int c) {
edges.emplace_back(u, v, c);
int edge_idx = (int) edges.size() - 1;
G[u].push_back(edge_idx);
}
然后,根据刚才的分析,我们从终点(idx = n - 1)开始倒着执行 BFS,依次求出每个节点 u 到终点的最短距离 dis[u]。
void rev_bfs() {
memset(vis, 0, sizeof(vis));
dis[n - 1] = 0;
vis[n - 1] = true;
queue<int> q;
q.push(n - 1);
while (!q.empty()) {
int u = q.front();
q.pop();
for (int i = 0; i < G[u].size(); i++) {
int e = G[u][i];
int v = edges[e].v;
if (!vis[v]) {
vis[v] = true;
dis[v] = dis[u] + 1;
q.push(v);
}
}
}
}
dis 计算完毕之后,我们从起点开始再执行一遍 BFS,找到字典序最小的边的序列。
vector<int> res; // 用来存放结果
// 从起点 (idx = 0) 开始 BFS,找到字典序最小的边的序列
void bfs() {
memset(vis, 0, sizeof(vis));
vis[0] = true;
res.clear();
vector<int> next;
next.push_back(0);
// 遍历每一个距离,就是在遍历每一个「下一步」
for (int i = 0; i < min_dis[0]; i++) {
int min_color = maxc;
for (int u : next) {
for (int k = 0; k < G[u].size(); k++) {
int e = G[u][k];
int v = edges[e].v;
if (min_dis[u] == min_dis[v] + 1) {
// 说明 (u,v) 是最短路径上的一条边
// 从中选择颜色编号最小的作为理想路径中的边
min_color = min(min_color, edges[e].c);
}
}
}
res.push_back(min_color);
vector<int> next2;
for (int u : next) {
for (int k = 0; k < G[u].size(); k++) {
int e = G[u][k];
int v = edges[e].v;
// 将上面找到的理想路径中的边(即 color == min_color)的终点扔进 vector 用于 BFS
if (min_dis[u] == min_dis[v] + 1 && !vis[v] && edges[e].c == min_color) {
next2.push_back(v);
vis[v] = true;
}
}
}
next = next2;
}
printf("%d\n", (int) res.size());
printf("%d", res[0]);
for (int i = 1; i < res.size(); i++) printf("%d", res[i]);
printf("\n");
}
注意,这里的 BFS 没有用 queue 来实现,而采用 vector。这是因为我们已经清晰地知道从起点到终点的最短路径的长度,我们只需要沿着几个可能存在的候选道路坚定地往下走,就可以保证一定能到达终点。这一轮 BFS 的核心是找到颜色编号最小的每一条边。
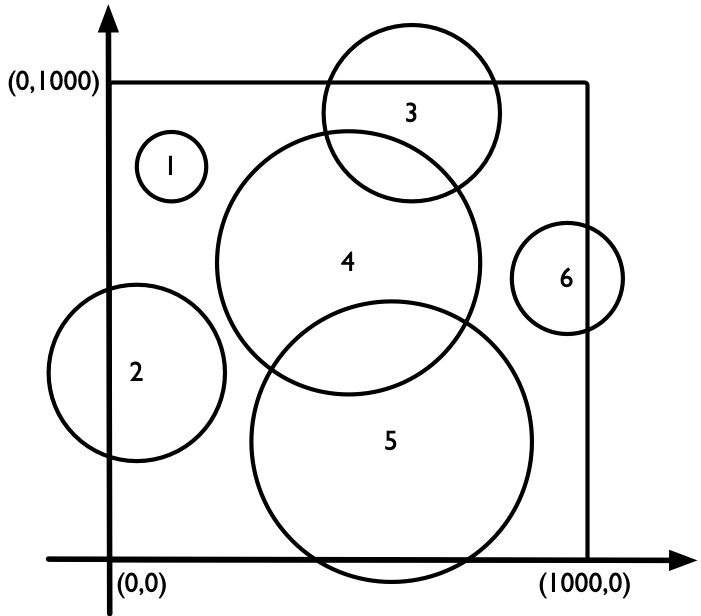
有一个 $1000 \times 1000$ 的正方形战场,战场西南角的坐标为 $(0,0)$,西北角的坐标为 $(0,1000)$。战场上有 $n$ 个敌人,第 $i$ 个敌人的坐标为 $(x_i, y_i)$,攻击范围为 $r_i$。为了避开敌人的攻击,在任意时刻,你与每个敌人的距离都必须严格大于他的攻击范围。你的任务是从战场的西边($x=0$ 的某个点)进入,东边($x=1000$ 的某个点)离开。如果有多个位置可以进出,你应当求出最靠北的位置。输入每个敌人的 $x_i, y_i, r_i$,输出进入战场和离开战场的坐标。
这个问题可以抽象为:正方形内有 $n$ 个圆形障碍物(可以和正方形的边相交),能否从正方形的左边界走到右边界?如果我们将正方形看成节点,并认为「当两个正方形相交时,它们之间就存在一条无向边」。由此,这些圆形可以组成一个或多个连通图。那么,能否从左侧到达右侧,要看是否有一个连通图将正方形切割成东西两个子部分,即这个连通图最上方的圆和正方形上边界接壤、最下面的圆和正方形下边界接壤。图 11 给出了这种连通图的一个案例。如何实现这个判断?一种方法是,对于每个和上边界相交的圆,我们基于 DFS 逐渐往下走,直到最下面一个圆。如果这个圆和下边界相交,则说明这样的连通图存在,我们无法穿越战场。我们先解决这个问题,然后再考虑从哪里进入和出去。
我们先准备基本数据结构和方法:
const int maxn = 1000 + 5;
const double W = 1000.0;
int n, vis[maxn];
double x[maxn], y[maxn], r[maxn];
bool ok;
// 判断两个敌人的攻击范围是否交叉(两个圆是否相交、两个节点之间是否存在边)
bool intersect(int c1, int c2) {
return sqrt(pow(x[c1] - x[c2], 2) + pow(y[c1] - y[c2], 2)) < r[c1] + r[c2];
}
dfs() 函数如下:
// 从北到南通过 dfs 判断是否存在一条连通南北的「踏脚石道路」
bool dfs(int c) {
if (vis[c]) return false;
vis[c] = 1;
// 和下边界相交
if (y[c] - r[c] < 0) return true;
for (int v = 0; v < n; v++) {
if (intersect(c, v) && dfs(v)) return true;
}
// 后续处理逻辑...
return false;
}
在主函数中,我们需要启动对 dfs() 的调用:
int main() {
// 读取输入...
for (int c = 0; c < n; c++) {
// 对于每一个和上边界相交的节点,
// 我们都需要判断从它开始形成的连通图是否会阻断东西战场
if (y[c] + r[c] >= W && dfs(c)) {
ok = false;
break;
}
}
// 后续处理逻辑...
}
当 ok = true 时,我们可以穿越战场。可以要从哪里进入、从哪里出去呢?图 12 到图 14 给出了所有的可能情况。题目要求我们从尽可能靠北的位置离开战场。我们不妨也从最靠北的位置进入战场。如图 12 所示,如果左右边界最上面的圆不和上边界相交,则从顶端进出即可。如果左右边界最上面的圆和上边界相交,则找到圆和左右边界的下交点,从这些点进出。和判断战场是否被分割遵循一样的思路,我们应该分别在左右边界上找到「从和上边界相交的圆开始的」连通图,并将这个连通图最下面的圆和边界的下交点作为进出点。这就是我们所能得到的最靠北的合法位置。
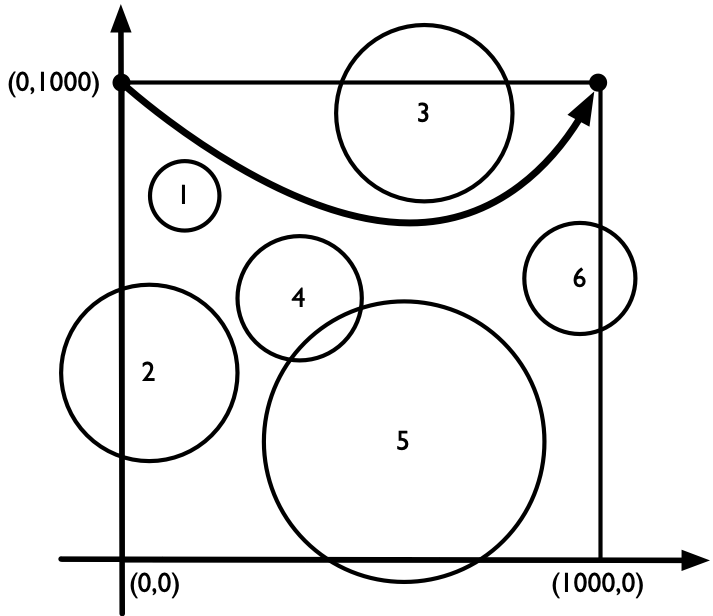
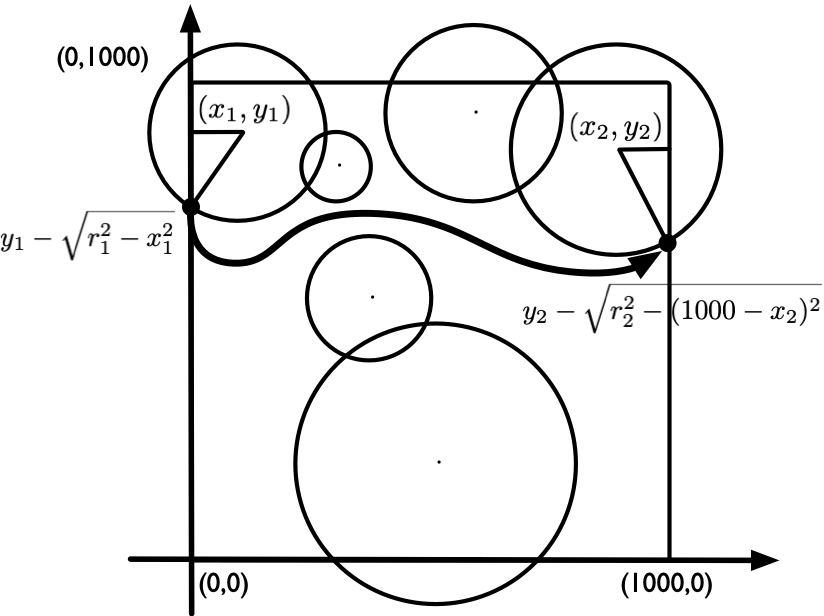
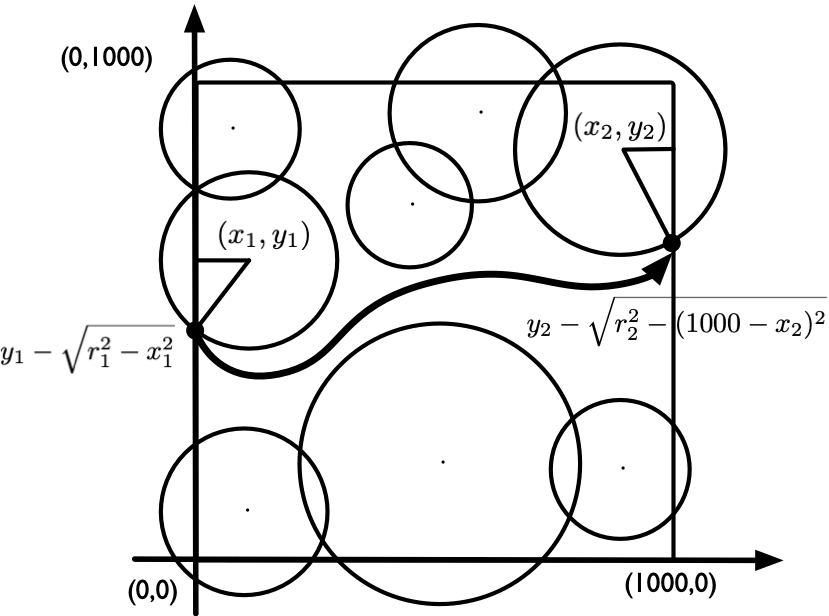
图 13 和图 14 中左右进出点的计算方式实现如下:
double left, right;
void check_circle(int c) {
// 该圆和左边界相交,求出两个交点中更低的那个交点的高度(y 值)
if (x[c] - r[c] < 0) {
left = min(left, y[c] - sqrt(pow(r[c], 2) - pow(x[c], 2)));
}
// 该圆和右边界相交,求出两个交点中更低的那个交点的高度(y 值)
if (x[c] + r[c] > W) {
right = min(right, y[c] - sqrt(pow(r[c], 2) - pow(W - x[c], 2)));
}
}
最后,我们只需要将 check_circle() 的调用插入 dfs() 函数的末尾即可。本题完整代码请参见 aoapc/ch06/e6-22。
例题 7:雕塑(Sculpture, ACM/ICPC NWERC 2008, UVa 12171)
某雕塑由 $n$ 个边平行于坐标轴的长方体组成。每个长方体用 6 个整数 $x_0, y_0, z_0, x, y, z$ 表示(均为 1~500 的整数),其中 $x_0$ 为长方体的顶点中 $x$ 坐标的最小值, $x$ 表示长方体在 $x$ 方向的总长度。其他 4 个值的定义类似。你的任务是统计这个雕塑的体积和表面积。注意,雕塑内部可能会有密闭空间,其体积应该计算在总体积中,但从外部看不见的面不应计入表面积。雕塑可能会由多个连通块组成。
这道题目的本质仍然是「寻找连通块」,尽管需要探索的空间从二维数组变成了三位数组。此外,和例题 2 类似,我们需给背景(空气)和雕塑组成的各个连通块分别求出来并编号。除了以上关于图的操作,我们还需要通过离散化的操作降低问题的计算规模,否则会超时。整体执行思路如下:
- 在三维数组周围加上一圈 “空气”(背景);
- 找到三维数组中所有的 “空气”,计算这些空气组成的体积和内表面积。这个内表面积就是雕塑的外表面积,总体积减去空气体积就是雕塑的体积。
完整代码请参见 aoapc/ch06/e6-18。
例题 8:骰子难题(A dicey problem, ACM/ICPC World Finals 1999, UVa 810)
如图 15 所示,左边是一个迷宫,右边是一个骰子。你的任务是把骰子放在起点(骰子顶面和正面由输入决定)经过若干次滚动之后回到起点。每次骰子只能往和其顶面数字相同的格子移动,除非这个格子是五角星——不论骰子顶面是什么数字,它总可以向内容为五角星的格子滚动。输入一个 $R$ 行 $C$ 列的迷宫,起点坐标以及骰子顶面、正面的数字,输出一条可行的路径。
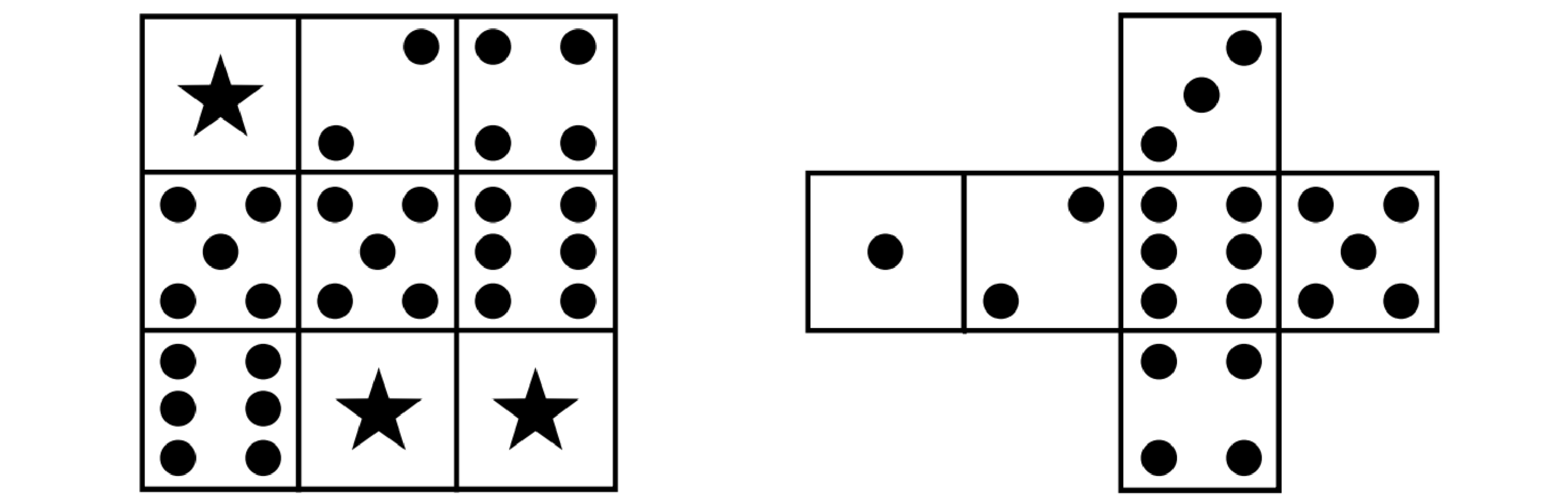
本题本质上是通过 BFS 求最短路径。难点是骰子的移动以及要设计四维的 vis 矩阵(当前所在格子的横纵坐标以及骰子的顶面与正面)。
首先,我们准备数据结构和一些基础操作:
const int maxn = 10 + 5;
int n, m; // 迷宫大小
int die[6 + 1][6 + 1]; // 用于存放将骰子逆时针转动 90 度后正面的数值
int vis[maxn][maxn][6 + 1][6 + 1]; // 四维的 vis 矩阵
int sx, sy, u, f; // 起点的坐标以及起点的顶面和正面
int maze[maxn][maxn]; // 存放迷宫内每个格子的数值
int dr[] = {-1, 1, 0, 0};
int dc[] = {0, 0, -1, 1};
struct State {
// 状态由 4 个元素组成,当前所在格子的坐标以及骰子的顶面和正面
int x, y, u, f;
int pre;
State() {}
State(int x, int y, int u, int f, int pre) : x(x), y(y), u(u), f(f), pre(pre) {}
} states[10000 + 5];
// 将骰子逆时针转动 90 度,面向我们的面的数值
void init() {
die[1][2] = 4; die[1][3] = 2; die[1][4] = 5; die[1][5] = 3;
die[2][1] = 3; die[2][3] = 6; die[2][4] = 1; die[2][6] = 4;
die[3][1] = 5; die[3][2] = 1; die[3][5] = 6; die[3][6] = 2;
die[4][1] = 2; die[4][2] = 6; die[4][5] = 1; die[4][6] = 5;
die[5][1] = 4; die[5][3] = 1; die[5][4] = 6; die[5][6] = 3;
die[6][2] = 3; die[6][3] = 5; die[6][4] = 2; die[6][5] = 4;
}
// d 是 4 个滚动方向,上下左右依次编号为 0 1 2 3
// roll 函数给出了,当顶面为 vu、正面为 vf 时,向着 d 方向滚动一格之后骰子的新顶面和新正面
void roll(int &vu, int &vf, int d) {
if (d == 0) {
int tmp = vf;
vf = 7 - vu;
vu = tmp;
} else if (d == 1) {
int tmp = vu;
vu = 7 - vf;
vf = tmp;
} else if (d == 2) {
vu = 7 - die[vu][vf];
} else if (d == 3) {
vu = die[vu][vf];
}
}
当以上关于骰子移动的操作正确设计之后,本题就没有什么难度了。只需要来一轮 BFS 即可。
typedef pair<int, int> pos;
vector<pos> trace; // 存放路径
// 根据每个状态中的 pre(父指针)回溯到起点(将整个经过的 pos 按照顺序插入 trace 中)
void dfs(int idx) {
if (idx == -1) return;
dfs(states[idx].pre);
trace.emplace_back(states[idx].x, states[idx].y);
}
void bfs() {
trace.clear();
int head = 0, rear = 0;
states[rear++] = State(sx, sy, u, f, -1);
memset(vis, 0, sizeof(vis));
vis[sx][sy][u][f] = 1;
while (head < rear) {
State s = states[head++];
for (int i = 0; i < 4; i++) {
State s2 = s;
s2.x += dr[i];
s2.y += dc[i];
if (s2.x <= 0 || s2.x > n || s2.y <= 0 || s2.y > m) continue; // 往这个方向滚动会出界
if (maze[s2.x][s2.y] != -1 && s.u != maze[s2.x][s2.y]) continue; // 往这个方向滚动不合法
if (s2.x == sx && s2.y == sy) {
dfs(head - 1);
// 最后回到了起点,别忘了将起点也插入到 trace 中
trace.emplace_back(sx, sy);
for (int j = 0; j < (int) trace.size(); j++) {
if (j % 9 == 0) printf("\n");
printf("(%d,%d)%c", trace[j].first, trace[j].second, j == (int) trace.size() - 1 ? '\n' : ',');
}
return;
}
// 滚动骰子
roll(s2.u, s2.f, i);
if (vis[s2.x][s2.y][s2.u][s2.f]) continue;
vis[s2.x][s2.y][s2.u][s2.f] = 1;
s2.pre = head - 1;
states[rear++] = s2;
}
}
cout << endl << "No Solution Possible" << endl;
}
本题的完整代码请参见 aoapc/ch06/p6-12。
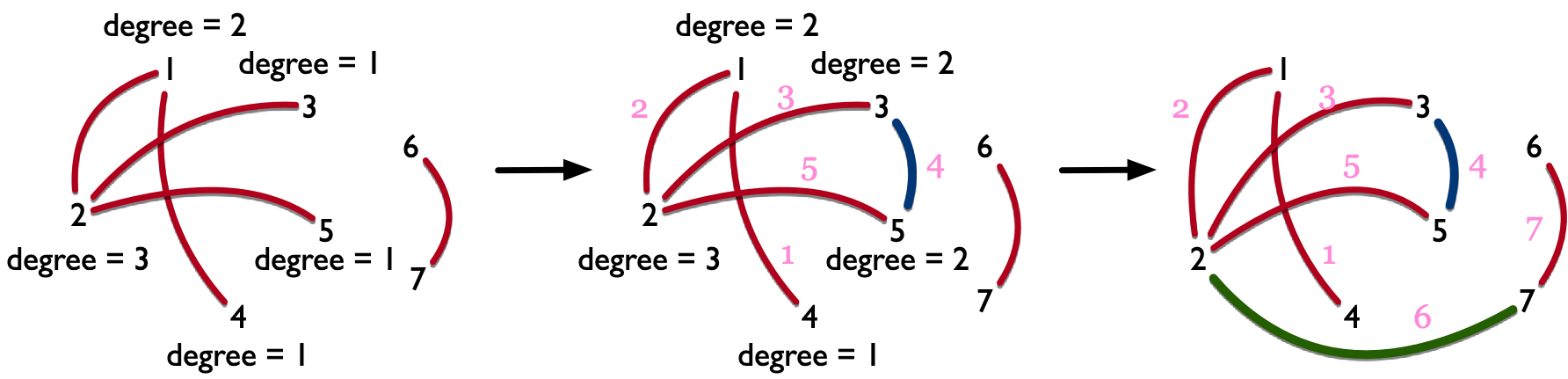
例题 9:检查员的难题(Inspector’s dilemma, ACM/ICPC Dhaka 2007, UVa 12118)
某国家有 $V$ 个城市,每两个城市之间都有一条双向道路直接相连,长度为 $T$。你的任务时找一条最短的道路(起点和终点任意),使得该道路经过 $E$ 条指定的边。首先输入 $V$、$E$、$T$,然后在接下来的 $E$ 行输入每条边的起点和终点,输出最短道路的长度。如图 16 所示,若 $V = 5, E = 3, T = 1$,指定的 3 条边为 1-2、1-3、4-5,则最优道路为 3 1 2 4 5,长度为 4。
这道题看起来是 BFS 求最短路径,其实是欧拉道路问题。需要通过构造边使得构建出来的图具有欧拉道路。首先,我们将全连通图中的所有边都去掉,然后只将指定的无向边添加上,由此我们形成了一个新的图。然后,我们需要通过 DFS 检查这个图中有几个连通子图,并依次判定每个连通子图中奇点的个数(注意,奇点的个数必然为偶数)。如果这个连通子图中没有奇点或有两个奇点,则这个连通子图中存在欧拉道路。如果这个连通子图中的奇点个数超过 2,不妨设为 $x$,则我们只需要添加 $\frac{x - 2}{2}$ 条边就可以使得欧拉道路存在。
经过上述操作之后,每个连通子图内都存在了欧拉道路。我们现在只需要再将这些连通子图通过添加边的方式 “串联” 起来,就可以让整张图存在欧拉道路。而这样的欧拉道路,就是满足条件的最短道路。
图 17 形象地展示了以上流程。
2 总结
本文重点解析了图上的 DFS 和 BFS 及相关的应用,包含求连通块、最短路径、拓扑排序和欧拉回路。和树类似,图的 BFS 通常用队列来实现,而图的深度优先遍历和递归紧密关联。如何将一个问题化归为图问题,是本文试图传授的核心理念。
本文给出的仅仅是图中的基本问题和算法实现。在未来,我会继续撰写进阶图论模型与实现,例如,最小生成树、Dijkstra 算法、Bellman-Ford 算法等。
最后
本文改写自刘大爷的经典教材《算法竞赛入门经典(第二版)》的第六章的部分内容。此外, 图 5 和图 6 来自 UVa 的官方网站(参见对应的链接)。
转载申请

本作品采用 知识共享署名 4.0 国际许可协议 进行许可,转载时请注明原文链接。您必须给出适当的署名,并标明是否对本文作了修改。